asmVisはSPEのパイプライン上で命令がどのようにスケジューリングされているかを可視化してプログラムの最適化具合を一目瞭然にできるツールです。
ダウンロード
asmVisはIBMの以下のサイトで公開されています。IBMアカウントを登録する必要がありますが、誰でも無償で登録、ダウンロードできます。
IBM Assembly Visualizer for Cell Broadband Engine
インストール・起動
asmVisはJavaアプリケーションなので、まずはJavaの実行環境をインストールします。
端末(roxterm等)にコマンドを入力して作業を行います。
(Ubuntu 10.04の場合)
sudo apt-get -y --no-install-recommends install openjdk-6-jdk icedtea6-plugin
(Fedora 13の場合)
su -c 'yum install java-1.6.0-openjdk-devel java-1.6.0-openjdk-plugin'
ダウンロードしたasmVisのzipファイルを解凍します。
unzip asmvis.zip
実行します。
java -jar asmvis-20080310.jar
使い方
asmVisの使い方とパイプラインの最適化の方法はIBM Developer Worksの以下のサイトで解説されています。
Assembly Visualizer を活用した SPU コードの高速化: 第 1 回 asmVis を試してみよう
Assembly Visualizer を活用した SPU コードの高速化: 第 2 回 パイプラインを最適化する
サンプルプログラム
asmVisを使ってSPEのLS上でのメモリコピーのプログラムをチェックしてみます。
(SpursEngine WinFast PxVC1100 Linux SDK用プログラム)
ダウンロード:
spurs_ls_test.tar.gz
SPEプログラム
spe.c
#include <stdio.h>
#include <string.h>
#include <spurs/spsa/spsa.h>
#include <spu_mfcio.h>
#include <spu_intrinsics.h>
#define DECREMENTER_INIT 0xffffffff
char buffer[0x20000] __attribute__((aligned(128)));
// vector単位でコピー(SIMD、ループアンローリングで最適化)
void cpy_optimise(void * dst, void * src, unsigned int size)
{
vector unsigned int * vdst = dst;
vector unsigned int * vsrc = src;
unsigned int sizev = size >> 4;
unsigned int to = sizev / 7;
unsigned int i;
unsigned int j = 0;
for (i = 0; i < to; i++)
{
register vector unsigned int temp[7];
temp[0] = vsrc[j + 0];
temp[1] = vsrc[j + 1];
temp[2] = vsrc[j + 2];
temp[3] = vsrc[j + 3];
temp[4] = vsrc[j + 4];
temp[5] = vsrc[j + 5];
temp[6] = vsrc[j + 6];
vdst[j + 0] = temp[0];
vdst[j + 1] = temp[1];
vdst[j + 2] = temp[2];
vdst[j + 3] = temp[3];
vdst[j + 4] = temp[4];
vdst[j + 5] = temp[5];
vdst[j + 6] = temp[6];
j += 7;
}
// 半端な残りを処理
for (i = j; i < sizev; i++)
{
vdst[i] = vsrc[i];
}
}
// vector単位で単純にコピー
void cpy_vec(void * dst, void * src, unsigned int size)
{
vector unsigned int * vdst = dst;
vector unsigned int * vsrc = src;
unsigned int sizev = size >> 4;
unsigned int i;
for (i = 0; i < sizev; i++)
{
vdst[i] = vsrc[i];
}
}
// memcpyでコピー
void cpy_memcpy(void * dst, void * src, unsigned int size)
{
memcpy(dst, src, size);
}
// 1バイトずつ単純にコピー
void cpy_byte(void * dst, void * src, unsigned int size)
{
char * cdst = dst;
char * csrc = src;
unsigned int i;
for (i = 0; i < size; i++)
{
cdst[i] = csrc[i];
}
}
int main(vector unsigned int arg0, vector unsigned int arg1, vector unsigned int arg2)
{
unsigned int start, end;
// SPU Decrementerに初期値をセット
spu_writech(SPU_WrDec, DECREMENTER_INIT);
// 計測開始
start = spu_readch(SPU_RdDec);
// 実行
cpy_optimise(buffer + 0x10000, buffer, 0x10000);
// 計測終了
end = spu_readch(SPU_RdDec);
// 結果表示
printf("optimized LS memory copy: %f GB/s\n", (float)0x10000 / (float)(1024 * 1024 * 1024) / ((float)(start - end) / 16666666.7f));
// 参考:vector単位で単純にコピーした場合
spu_writech(SPU_WrDec, DECREMENTER_INIT);
start = spu_readch(SPU_RdDec);
cpy_vec(buffer + 0x10000, buffer, 0x10000);
end = spu_readch(SPU_RdDec);
printf("simple vector copy: %f GB/s\n", (float)0x10000 / (float)(1024 * 1024 * 1024) / ((float)(start - end) / 16666666.7f));
// 参考:memcpyを使った場合
spu_writech(SPU_WrDec, DECREMENTER_INIT);
start = spu_readch(SPU_RdDec);
cpy_memcpy(buffer + 0x10000, buffer, 0x10000);
end = spu_readch(SPU_RdDec);
printf("memcpy: %f GB/s\n", (float)0x10000 / (float)(1024 * 1024 * 1024) / ((float)(start - end) / 16666666.7f));
// 参考:1Byteずつ単純にコピーした場合
spu_writech(SPU_WrDec, DECREMENTER_INIT);
start = spu_readch(SPU_RdDec);
cpy_byte(buffer + 0x10000, buffer, 0x10000);
end = spu_readch(SPU_RdDec);
printf("simple byte copy: %f GB/s\n", (float)0x10000 / (float)(1024 * 1024 * 1024) / ((float)(start - end) / 16666666.7f));
return 0;
}
ホストプログラム
main.cpp
#include <iostream>
#include <fstream>
#include <memory>
#include <stdlib.h>
#include <spurs/spha/spha.h>
#include <spurs/common/byte_order.h>
#include <spurs/sp3/sp3_cmdif.h>
#define NUM_OF_SPE 1
using namespace std;
// SPEプログラムファイル名
const char * spe_program_name = "spe.elf";
int main(int argc, char ** argv)
{
spha_session_t session;
// セッションの作成
spha_create_session(NULL, &session);
// 通信路を確立
spha_connect_session(session);
// SPEプログラムファイルをオープン
ifstream fp(spe_program_name, ios::binary);
// ファイルサイズを調べる
fp.seekg(0, ios::end);
uint32_t spe_program_size = fp.tellg();
fp.seekg(0, ios::beg);
// バッファサイズを128の倍数に揃える
uint32_t buffer_size = (spe_program_size + 127) & ~127;
// SpursEngine側ローカルメモリ領域の確保
// SPEプログラム格納用
spha_object_t buffer_obj;
spha_create_memory(session, 0, 0, 0, buffer_size, 0, &buffer_obj);
// データ格納用(64MB)
uint32_t buffer_size_data = 0x4000000;
spha_object_t buffer_obj_data;
spha_create_memory(session, 0, 0, 0, buffer_size_data, 0, &buffer_obj_data);
// メモリオブジェクトをマップ
uint32_t buffer_ea, buffer_ea_data;
spha_map_memory(session, buffer_obj, 0, 0, 0, buffer_size, 0, &buffer_ea);
spha_map_memory(session, buffer_obj_data, 0, 0, 0, buffer_size_data, 0, &buffer_ea_data);
// ホスト側バッファを確保(128バイト・アライン)
// SPEプログラム格納用
char * buffer;
int err = posix_memalign((void **)&buffer, 128, buffer_size);
if (err)
{
abort();
}
// SPEプログラムファイルをロード
fp.read(buffer, spe_program_size);
// SpursEngine側ローカルメモリに転送
uint32_t transfer_size = buffer_size;
spha_data_transfer_to(session, buffer_obj, 0, buffer, &transfer_size);
// ホスト側バッファを解放
free(buffer);
// SPEプログラムローダに与える引数をセット
// エンディアン変換して渡す
uint32_t loader_arg[4];
loader_arg[0] = spurs_convert_ui32(buffer_ea);
loader_arg[1] = spurs_convert_ui32(buffer_size);
loader_arg[2] = 0;
loader_arg[3] = 0;
spha_thread_t spe_th[NUM_OF_SPE];
for (int i = 0; i < NUM_OF_SPE; i++)
{
// SPEスレッドを作成
spha_create_spe_thread(session, ~0, 0, SP3_SPE_LOADER_DEFAULT, loader_arg, sizeof(loader_arg), &spe_th[i]);
// SPEのmain()に与えるパラメーター
uint32_t arg[12];
arg[0] = spurs_convert_ui32(buffer_ea_data);
// SPEスレッドを実行状態にする
spha_resume_spe_thread(session, spe_th[i], 0, SP3_SPE_THREAD_RESUME_DEFAULT_ENTRY, arg, sizeof(arg), NULL, NULL, NULL);
}
for (int i = 0; i < NUM_OF_SPE; i++)
{
// SPEスレッドの終了を待つ
spha_wait_spe_thread(session, spe_th[i], NULL, NULL, NULL);
// SPEスレッドの破棄
spha_delete_spe_thread(session, spe_th[i]);
}
// メモリオブジェクトをアンマップ
spha_unmap_memory(session, buffer_ea, 0);
spha_unmap_memory(session, buffer_ea_data, 0);
// SpursEngine側ローカルメモリ領域を解放
spha_delete_object(session, buffer_obj);
spha_delete_object(session, buffer_obj_data);
// セッションの通信路を切断
spha_close_session(session);
// セッションの破棄
spha_delete_session(session);
return 0;
}
実行方法・実行結果
解凍:
tar xzf spurs_ls_test.tar.gz
cd spurs_ls_test
コンパイル:
make
実行:
./main
結果:
SIMD化、ループアンローリングで最適化した場合
optimized LS memory copy: 10.380128 GB/s
vector単位で単純にコピーした場合
simple vector copy: 2.481104 GB/s
ライブラリのmemcpyを使用した場合
memcpy: 1.859694 GB/s
byte単位で単純にコピーした場合
simple byte copy: 0.082169 GB/s
SIMD化、ループアンローリングで最適化した場合、memcpyの5.58倍高速化できています。
SIMD化してもループアンローリングしなければ約4分の1、byte単位で単純にコピーした場合では126分の1の性能となりました。
SPEでは、メモリをコピーするだけの極めて単純なプログラムでさえ、実装方法によってこれだけの差が出ます。SPEの能力を100%発揮させるためには、プロセッサ内部のパイプラインの命令スケジューリングまで意識した積極的な最適化を行う必要があります。
(現在はOpenCL, OpenMP, CellSs等、ある程度までそれを自動化できるソリューションもあります。)
逆に言えば、SPEはSIMD化、ループアンローリング、並列化等の最適化の効果が現れやすいアーキテクチャであると言えます。
上記プログラムをasmVisでチェック
makeすると「spe.s」が出力されるので、これをasmVisで開いてチェックします。(File->Open)
「spe.s」全体を開くこともできますが、ループ部分のみをテキストエディタ等で切り出して読み込ませるとループ直前の命令の依存性の影響を無視して実質的なループ実行中の命令スケジューリングを解析できます。ループの1回目ではストールが発生しても2回目以降は発生しないような状況がよくあります。
以下のようにループ部分のラベルから分岐命令までを切り出します。
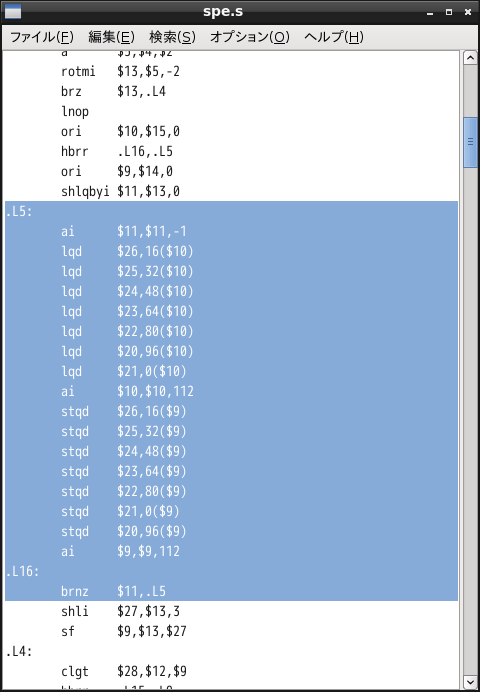
切り出したソースをtest.s等のファイル名で保存して、これをasmVisで開きます。
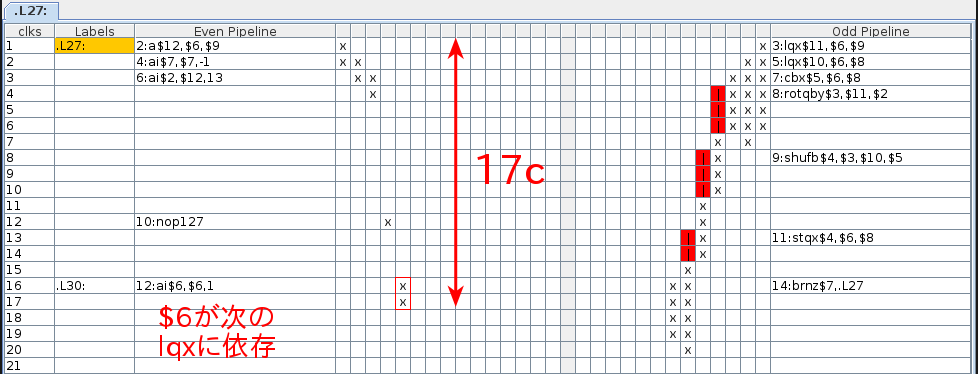
●byte単位で単純にコピーした場合のループ部分

拡大表示
SPEはbyte単位のロード・ストア命令がないのでローテートやシャッフル等複雑な工程が入っています。また、依存性によるストール(赤いマス)も多く発生しています。また、最後のai $6,$6,1の$6(レジスタ)が次のループの最初の命令に依存するので1cycleストールします。これで1byteにつき17cycleかかっているので理論値は以下のように計算できます。(SpursEngine PxVC1100のSPEのクロック:1.5GHzで計算しています。)
1 byte / 17 cycle x 1.5 GHz x 0.931323 = 0.0821756 GB/s
(0.931323 = 1000 x 1000 x 1000 / 1024 / 1024 / 1024)
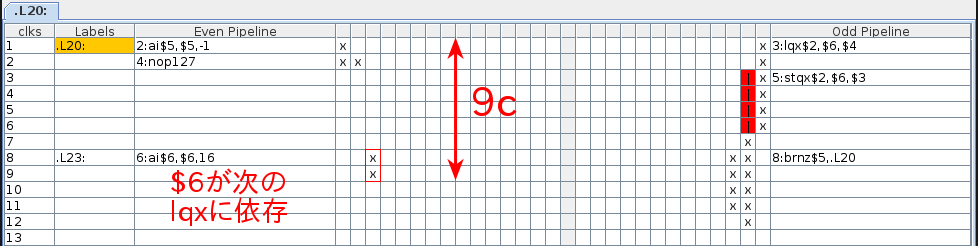
●vector単位で単純にコピーした場合のループ部分
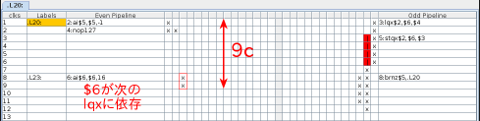
拡大表示
命令数は6命令と最も短く、偶数パイプライン・奇数パイプラインの組で見ると3cycle分しかありませんが、ロードとストアの依存性(ロードが完全に完了してからストアが発行される)により5cycleのストールが発生しています。また、最後のai $6,$6,16の$6が次のlqx $2,$6,$4に依存するので1cycleストールして合計9cycleで1vector(16byte)なので理論値は以下のようになります。
(本当は5cycleのストールが発生しているはずですがstqxの位置が1cycle分下にずれているので4cycleのストールのように見えてしまっています。asmVisのバグかも知れません。)
16 byte x 1 vector / 9 cycle x 1.5 GHz x 0.931323 = 2.483528 GB/s
●SIMD化、ループアンローリングで最適化した場合のループ部分
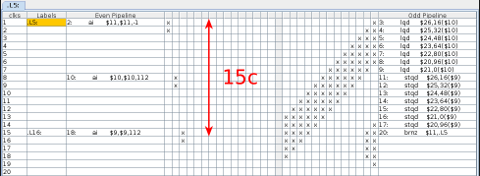
拡大表示
1回ずつロードとストアを繰り返すのではなく、7vector分一気にレジスタにロードしてからストアすることにより、依存性によるストールを防止できています。15cycleで7vector処理できているので(この部分のみの)理論値は以下のようになります。
16 byte x 7 vector / 15 cycle x 1.5 GHz x 0.931323 = 10.430818 GB/s
ところでこのプログラム、1回のループで8や16vectorではなく、なぜ7vectorという中途半端な数になっているかというと、8vector以上にするとSPEの仕様(*1)上プリフェッチヒント命令(hbrp)が挿入されるので、かえって少し遅くなってしまうためです。実際にどうなるか試してみてください。
(*1)詳しくは
Cell/B.E.公開情報のSPUstall_app_v10_j.pdfを参照してください。
今回の例では単にメモリからロードしてそのままストアするだけで、ほとんどの命令が奇数パイプライン(右側)に入るため、偶数パイプライン(左側)がスカスカです。つまりこの例ではSPEの能力のほとんど半分しか使っていません。
他の一般的なプログラムでは当然数値演算等が入ってくるので左側にも命令が埋まることになります。
左側にも右側にも命令がぎっしりと詰まり、「x」が綺麗な45度のVの字に並んだ時、SPEは100%の能力を発揮していることになります。