回路規模が小さく高クロックで動作するCPUの設計
2024/06/02 対象基板をKV260に変更、UARTインターフェースを追加
2018/12/02 default_code_mem.v をFPGA向け設定に修正
2018/11/25 新規公開
今回は、できる限り回路規模を小さく、できる限り高クロックで動作させることを主眼に置き、かつ、必要な命令を一通り備えた実用的なCPUを目指して設計しました。
FPGAのAMD Kria KV260、AMD Kintex UltraScale+ (最新のハイエンドFPGA、xcku3p-ffva676-3)で合成した場合の最小構成での回路規模と動作周波数は以下のようになりました。
| 機種 | 回路規模(CPU部分のみ) | Timing metした最大動作周波数 |
|---|---|---|
| AMD Kria KV260 | 50 CLB (181 LUTs) | 510 MHz(実機動作確認済) |
| Kintex UltraScale+ | 51 CLB (186 LUTs) | 710 MHz(Vivado上の評価) |
アーキテクチャー
コードサイズを小さくするために、今回は命令長を16bitにしました。レジスター幅のデフォルト値は16bitですがパラメーターで可変となっているのでアプリケーションの必要に合わせて32bitや64bitに変更できます。
回路規模の縮小、動作周波数向上のための工夫
- 深いパイプライン
動作周波数を上げるため深めの7段ステージパイプラインの設計にしました。また、完全なパイプライン設計にしているので最小1サイクルで命令を連続実行できます。
- 乗算命令とシフト命令は深いパイプラインで実行
テストの結果、乗算命令とシフト命令が特に遅延が大きいため、実行段で3〜4サイクルの遅延を許容する設計にし、パイプライン化した回路が生成されるようにしました。
- レジスターファイルをブロックRAMで構成可能
パイプラインはより深くなりますが、多くのレジスターを実装した場合でも回路規模が大きくなりません。(実際にBRAMが使用されるかどうかは実装時のオプションによります)
- オペコードのビット配置を最適化
単純に命令順に連番にするのではなく、デコードなどの条件比較の回路がより単純化するようにビットの並びを最適化します。例えばオペコードの上位2bitが00の命令はレジスターに影響を与えないタイプの命令をまとめ、分岐命令は上位3bitを001に統一しています。
- 複雑な回路を複数サイクルに分割してパイプライン化
合成ツールのタイミングレポートをよく見て複雑になっている部分を特定します。例えばQuartusでは非常に高いクロックで合成してみるとTiming metしなかったパスの情報が出てくるので、そこを複数サイクルでパイプライン実行する形に修正します。
- パイプライン設計をやりやすくするための記述上の工夫
パイプラインのステージごとにレジスター名をregister_name_s2というようにステージ番号をつけて管理し、ステージごとにalways文と宣言文をまとめて記述することにより、パイプライン構造を分かりやすくしてタイミングを間違えにくくします。この形で設計すると、各ステージの構造が一目瞭然になるので試行錯誤して処理を追加するような場合にも混乱が起きません。(たとえば〜_s5のレジスターへの代入に使用する条件や入力値は必ず〜_s4でなければいけませんし、そうするために〜_s3の値は前のステージで〜_s4 <= 〜_s3と遅延させておいてからs5ステージで使用するといった具合です。)
- 柔軟な実装オプション
実装する機能のON, OFFやデータ幅等の設定を実装時に簡単に変更できるように設計しました。レジスタ幅も16bitから32, 64, N bitまで自由自在に変更可能です。
Mini16-CPU 命令セットアーキテクチャー
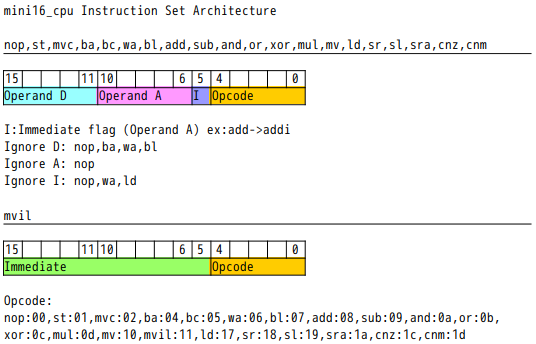
| Opcode | 機能 | 解説 |
|---|---|---|
| nop | None | |
| st | mem[reg_d] = reg_a | Store |
| mvc | if (reg_0) reg_d = reg_a | Move Conditional |
| ba | pc = reg_a | Branch Absolute |
| bc | if (reg_d) pc = reg_a | Branch Conditional |
| wa | wait(im_a) | この命令の2命令後にnopをim_a(4-15)回挿入したのに相当するウェイトを入れる |
| bl | pc = reg_a; reg_d = pc + 6 | Branch and Link |
| add | reg_d += reg_a | |
| sub | reg_d -= reg_a | |
| and | reg_d &= reg_a | |
| or | reg_d |= reg_a | |
| xor | reg_d ^= reg_a | |
| mul | reg_d *= reg_a | Multiply |
| mv | reg_d = reg_a | Move |
| mvil | reg_1 = im(11bit) | Move Immediate Long |
| ld | reg_d = mem[reg_a] | Load |
| sr | reg_d >>= reg_a | Shift Right |
| sl | reg_d <<= reg_a | Shift Left |
| sra | reg_d >>>= reg_a | Shift Right Arithmetic |
| cnz | if (reg_a != 0) reg_d = -1 else reg_d = 0 | Compare Not Zero |
| cnm | if (reg_a >= 0) reg_d = -1 else reg_d = 0 | Compare Not Minus |
即値命令
上記のOpcodeの末尾にiを追加したものは即値命令となります。Operand Aは5bitの符号付き即値として扱われ、それをレジスター幅にビット拡張した値で命令が実行されます。(nop,wa,mvil,ldを除く)
sli, sri, srai の有効シフト値は0から15となることに注意が必要です。
レジスター
PC: プログラムカウンター(内部レジスター)
R0: mvc命令の条件として参照されるレジスター。True:0以外, False:0
R1: mvil命令の代入先として使用されるレジスター。
R2 〜 R31: 汎用レジスター
命令配置制約
- 分岐命令(bc,bl,ba)の後の5命令は遅延スロットとなります。分岐命令の後5ステップの命令はそのまま実行され、6サイクル後に分岐先の命令が実行されます。通常は遅延スロットにはnopを置きますが、他の命令を置くこともできます。ただし条件分岐の有無に関わらず実行されることや複数回実行される場合があることに注意する必要があります。
例:
bc(R3, R4); // if (R3 != 0) PC = R4
nop();
nop();
nop();
nop();
nop(); // この命令まで実行されてから分岐先に飛ぶ
- 特定のレジスターに対して書き込んだ値が読み出し可能になるのは6サイクル後なので依存関係のある操作を行う命令の間に5つの別の命令を置く必要があります。(他に何もなければnop)
例:
add(3, 4);// R3 = R3 + R4。以下のadd(3, 5);がR3の演算結果に依存
add(2, 6);// NOP以外に依存関係のない他の命令を入れても良い
sub(7, 8);
nop();
nop();
nop();
add(3, 5);// R3 = R3 + R5
- プログラムの最初の命令はnopである必要があります。
Application Binary Interface (ABI)
- スタック・ポインター
R31はスタック・ポインター格納用に予約します。
プログラムは開始時にデータメモリーの最終アドレスをスタック・ポインターにセットすることとします。
スタックは最終アドレスから開始アドレスに向かって成長させます。
関数はスタック・ポインターを呼び出し時点の値に復元してからリターンしなければいけません。 - リンク・レジスター
R2はリンク・レジスター格納用に予約します。
関数は入り口でリンク・レジスターの値を保存し、リターンする前にこれを復元しなければいけません。リンク・レジスターはBL命令実行時に変更されます。 - レジスター割り当て
R3からR7までは関数の引数や戻り値として使用します。順序は引数リストの左から、番号の若い順に割り当てます。揮発性(復元責任は呼び出し側)です。
R8からR23は揮発性の汎用レジスターとします。
R24からR30は非揮発性(呼び出された側が復元責任を持つ)の汎用レジスターとします。
Mini16-SoCについて
Mini16-CPUに命令メモリー、データメモリー、LEDなど周辺I/Oを接続してFPGAで1チップで実装したシステムです。
周辺デバイスはMini16-CPUからMMIOで制御する形になっています。(メモリーにアクセスするのと同じようにデバイスの制御レジスターのアドレスに対して書き込み、読み込みを行います。)
ターゲットボードについて
このプロジェクトは以下のFPGAボードに対応しています。
Terasic DE0-CV
Xilinx Kintex UltraScale+ (xcku3p-ffva676-3チップを対象にした合成、評価試験のみ)
論理合成・実行方法
ソースコードのダウンロード:mini16_cpu.tar.gz
●Ubuntuでのビルドに対応しています。gcc, make, OpenJDK8.0のパッケージをインストールしていることとします。
●KV260, Kintex UltraScale+の場合
Vivado/Vitis2023.2をインストールしているものとします。
Kintexはチップをターゲットにした合成テストのみの対応です。Vivado上で合成して回路規模やタイミング評価を確認できます。
ターミナルで、
tar xf mini16_cpu.tar.gz
各社のツールでプロジェクトファイルを開いて合成、転送します。
デフォルトでは合成されたCPUの上でLチカプログラムが走ります。
mini16_cpu/asm/Examples.java のコメントアウトされている部分を修正すればUARTでHelloWorldやカウンター値を出力するプログラムも実行できます。
プロジェクトディレクトリ:
AMD Kria KV260: mini16_cpu/kv260/
AMD Kintex UltraScale+: mini16_cpu/kintex_usp/
詳しい実行方法は、各ディレクトリのreadme.mdを参照してください。
合成結果はツールのバージョンや環境によってばらつきが出ることがあります。VivadoでTiming failした場合はCreate Run:ImplementationのRun Strategyを変更したりして何度か試してみてください。
Verilogシミュレータ「Icarus Verilog」でのシミュレーション
「Icarus Verilog」を使えばFPGAボードがなくても開発・シミュレーションを行うことができます。
「Icarus Verilogコンパイラを使う」の方法で iverilog と gtkwave をインストールし、
cd mini16_cpu/testbench
make run
でシミュレーションできます。出力された wave.vcd を gtkwave で開いて画面左側の信号リストから見たい信号を右側の波形画面へドラッグ&ドロップすれば信号波形を観察できます。
このCPUでプログラミングする方法
mini16_cpu/asm 以下にJava上で動作する簡易アセンブラが入っています。
実行にはOpenJDK 8.0以上のインストールが必要です。
AsmLibクラスを継承したクラスを作り、init()で初期化設定、program()にプログラム、data()にデータを記述します。AsmTop.javaも修正します。
mini16_cpuディレクトリに移動して make を実行するとプログラム・バイナリが出力されます。
詳しくはExamples.javaのソースコードを参照してください。
実装オプション
| オプション | 解説 |
|---|---|
| ENABLE_MVIL | MVIL命令を有効にします |
| ENABLE_MUL | MUL命令を有効にします |
| ENABLE_MULTI_BIT_SHIFT | 複数ビットのシフトを有効にします。オフでは1bitのみのシフトです |
| ENABLE_MVC | MVC命令を有効にします |
| ENABLE_WA | WA命令を有効にします |
| FULL_PIPELINED_ALU | 全ての命令の実行ステージをパイプライン化します。回路規模は増えますがパフォーマンスには有利です |
| DEPTH_I | 命令メモリーのサイズを指定します |
| DEPTH_D | データメモリーのサイズを指定します |
| WIDTH_D | レジスター、データメモリーのbit幅を指定します |
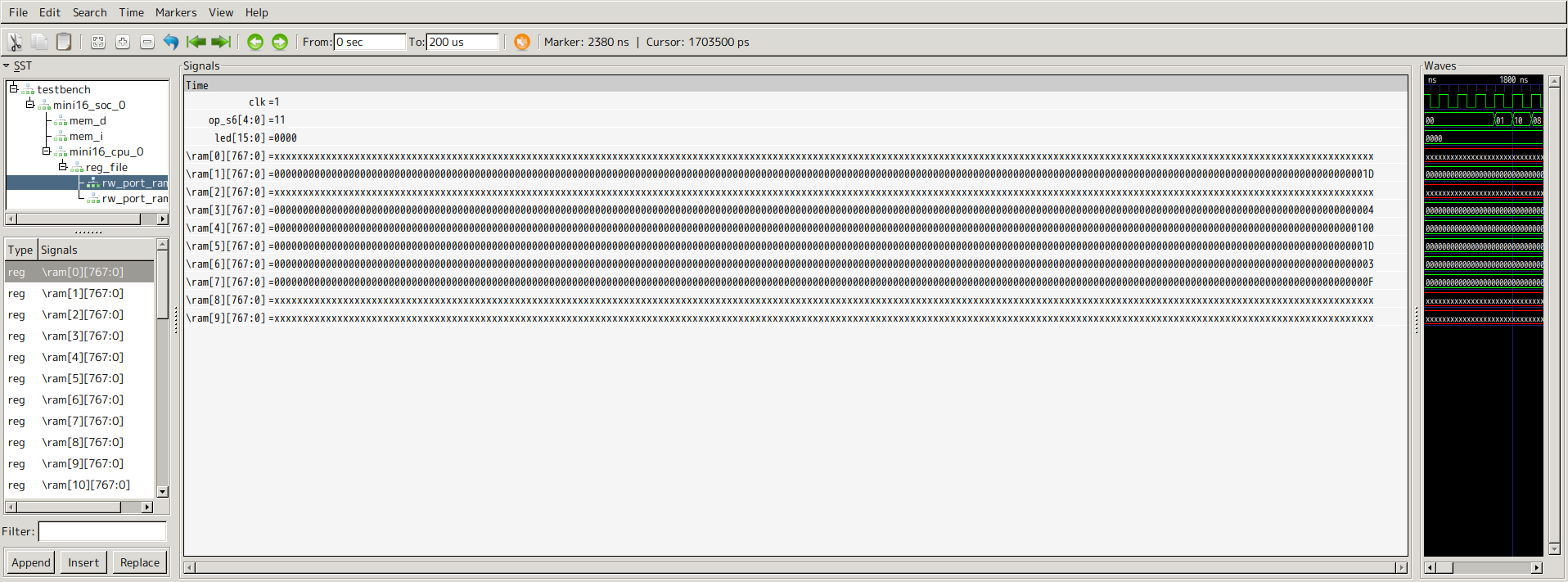
WIDTH_Dを変更するだけで簡単に128bit整数以上の演算ができるCPUを作れます。以下の画像は768bit整数の演算のシミュレーション結果です。
ソースコード
これらのソースコードはBSD 2-Clauseライセンスで公開します。
mini16_cpu.v : CPU本体
Copyright (c) 2018, miya
All rights reserved.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED.
IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
module mini16_cpu
#(
parameter WIDTH_I = 16,
parameter WIDTH_D = 16,
parameter DEPTH_I = 8,
parameter DEPTH_D = 8,
parameter DEPTH_REG = 5,
parameter REGFILE_RAM_TYPE = "auto",
parameter ENABLE_MVIL = 1'b0,
parameter ENABLE_MUL = 1'b0,
parameter ENABLE_MULTI_BIT_SHIFT = 1'b0,
parameter ENABLE_MVC = 1'b0,
parameter ENABLE_WA = 1'b0,
parameter ENABLE_INT = 1'b0,
parameter FULL_PIPELINED_ALU = 1'b0
)
(
input clk,
input reset,
input soft_reset,
output reg [DEPTH_I-1:0] mem_i_r_addr,
input [WIDTH_I-1:0] mem_i_r_data,
output reg [DEPTH_D-1:0] mem_d_r_addr,
input [WIDTH_D-1:0] mem_d_r_data,
output reg [DEPTH_D-1:0] mem_d_w_addr,
output reg [WIDTH_D-1:0] mem_d_w_data,
output reg mem_d_we
);
localparam TRUE = 1'b1;
localparam FALSE = 1'b0;
localparam ONE = 1'd1;
localparam ZERO = 1'd0;
localparam FFFF = {WIDTH_D{1'b1}};
localparam SHIFT_BITS = $clog2(WIDTH_D);
localparam BL_OFFSET = 1'd1;
localparam DEPTH_OPERAND = 5;
// opcode
localparam I_NOP = 5'h00; // 5'b00000;
localparam I_ST = 5'h01; // 5'b00001;
localparam I_MVC = 5'h02; // 5'b00010;
localparam I_BA = 5'h04; // 5'b00100;
localparam I_BC = 5'h05; // 5'b00101;
localparam I_WA = 5'h06; // 5'b00110;
localparam I_BL = 5'h07; // 5'b00111;
localparam I_ADD = 5'h08; // 5'b01000;
localparam I_SUB = 5'h09; // 5'b01001;
localparam I_AND = 5'h0a; // 5'b01010;
localparam I_OR = 5'h0b; // 5'b01011;
localparam I_XOR = 5'h0c; // 5'b01100;
localparam I_MUL = 5'h0d; // 5'b01101;
localparam I_MV = 5'h10; // 5'b10000;
localparam I_MVIL = 5'h11; // 5'b10001;
localparam I_LD = 5'h17; // 5'b10111;
localparam I_SR = 5'h18; // 5'b11000;
localparam I_SL = 5'h19; // 5'b11001;
localparam I_SRA = 5'h1a; // 5'b11010;
localparam I_CNZ = 5'h1c; // 5'b11100;
localparam I_CNM = 5'h1d; // 5'b11101;
// special register
localparam SP_REG_CP = 0;
localparam SP_REG_MVIL = 1;
// debug
`ifdef DEBUG
reg [DEPTH_I-1:0] mem_i_r_addr_d1;
reg [DEPTH_I-1:0] mem_i_r_addr_s1;
always @(posedge clk)
begin
mem_i_r_addr_d1 <= mem_i_r_addr;
mem_i_r_addr_s1 <= mem_i_r_addr_d1;
end
`endif
// stage 1 fetch
reg [WIDTH_I-1:0] inst_s1;
wire [DEPTH_OPERAND-1:0] reg_d_s1;
wire [DEPTH_OPERAND-1:0] reg_a_s1;
wire [4:0] op_s1;
wire is_im_s1;
assign reg_d_s1 = inst_s1[15:11];
assign reg_a_s1 = inst_s1[10:6];
assign is_im_s1 = inst_s1[5];
assign op_s1 = inst_s1[4:0];
generate
if (ENABLE_WA == TRUE)
begin
always @(posedge clk)
begin
if (reset == TRUE)
begin
inst_s1 <= ZERO;
end
else
begin
if (wait_en_s2 == TRUE)
begin
inst_s1 <= ZERO;
end
else
begin
inst_s1 <= mem_i_r_data;
end
end
end
end
else
begin
always @(posedge clk)
begin
if (reset == TRUE)
begin
inst_s1 <= ZERO;
end
else
begin
inst_s1 <= mem_i_r_data;
end
end
end
endgenerate
// stage 2 wait counter
wire wait_en_s2;
reg [4:0] wait_count_m1;
reg [9:0] wait_counter_s2;
generate
if (ENABLE_WA == TRUE)
begin
assign wait_en_s2 = (wait_counter_s2 == ZERO) ? FALSE : TRUE;
always @(posedge clk)
begin
if (reset == TRUE)
begin
wait_counter_s2 <= ZERO;
wait_count_m1 <= ZERO;
end
else
begin
if (op_s1 == I_WA)
begin
wait_counter_s2 <= reg_a_s1;
wait_count_m1 <= reg_a_s1 - ONE;
end
else
begin
if (wait_en_s2 == TRUE)
begin
wait_counter_s2 <= wait_counter_s2 - ONE;
end
end
end
end
end
endgenerate
// stage 2 set reg read addr
reg [DEPTH_REG-1:0] reg_addr_a_s2;
reg [DEPTH_REG-1:0] reg_addr_b_s2;
generate
if (ENABLE_MVC == TRUE)
begin
always @(posedge clk)
begin
reg_addr_b_s2 <= reg_a_s1[DEPTH_REG-1:0];
if (op_s1 == I_MVC)
begin
reg_addr_a_s2 <= SP_REG_CP;
end
else
begin
reg_addr_a_s2 <= reg_d_s1[DEPTH_REG-1:0];
end
end
end
endgenerate
// stage 2 delay
reg [4:0] op_s2;
reg is_im_s2;
reg [DEPTH_OPERAND-1:0] reg_d_s2;
reg [DEPTH_OPERAND-1:0] reg_a_s2;
always @(posedge clk)
begin
op_s2 <= op_s1;
is_im_s2 <= is_im_s1;
reg_d_s2 <= reg_d_s1;
reg_a_s2 <= reg_a_s1;
end
// stage 3 set dest reg addr
reg [DEPTH_REG-1:0] reg_addr_d_s3;
always @(posedge clk)
begin
if (reset == TRUE)
begin
reg_addr_d_s3 <= ZERO;
end
else
begin
if ((ENABLE_MVIL == TRUE) && (op_s2 == I_MVIL))
begin
reg_addr_d_s3 <= SP_REG_MVIL;
end
else
begin
reg_addr_d_s3 <= reg_d_s2[DEPTH_REG-1:0];
end
end
end
// stage 3 delay
reg [4:0] op_s3;
reg is_im_s3;
reg [DEPTH_OPERAND-1:0] reg_a_s3;
always @(posedge clk)
begin
op_s3 <= op_s2;
is_im_s3 <= is_im_s2;
reg_a_s3 <= reg_a_s2;
end
reg [DEPTH_OPERAND-1:0] reg_d_s3;
generate
if (ENABLE_MVIL == TRUE)
begin
always @(posedge clk)
begin
reg_d_s3 <= reg_d_s2;
end
end
endgenerate
// stage 4 fetch reg_data
wire [WIDTH_D-1:0] reg_data_a_s_s3;
wire [WIDTH_D-1:0] reg_data_b_s_s3;
reg [WIDTH_D-1:0] reg_data_a_s4;
reg [WIDTH_D-1:0] reg_data_b_s4;
always @(posedge clk)
begin
reg_data_a_s4 <= reg_data_a_s_s3;
if (reset == TRUE)
begin
reg_data_b_s4 <= ZERO;
end
else
begin
if ((ENABLE_MVIL == TRUE) && (op_s3 == I_MVIL))
begin
reg_data_b_s4 <= {reg_d_s3, reg_a_s3, is_im_s3};
end
else if (is_im_s3 == TRUE)
begin
reg_data_b_s4 <= $signed(reg_a_s3);
end
else
begin
reg_data_b_s4 <= reg_data_b_s_s3;
end
end
end
// stage 4 load address
always @(posedge clk)
begin
if (reset == TRUE)
begin
mem_d_r_addr <= ZERO;
end
else
begin
if (op_s3 == I_LD)
begin
mem_d_r_addr <= reg_data_b_s_s3;
end
end
end
// stage 4 delay
reg [4:0] op_s4;
reg [DEPTH_REG-1:0] reg_addr_d_s4;
always @(posedge clk)
begin
op_s4 <= op_s3;
reg_addr_d_s4 <= reg_addr_d_s3;
end
// stage 5 execute store
always @(posedge clk)
begin
if (reset == TRUE)
begin
mem_d_w_addr <= ZERO;
mem_d_w_data <= ZERO;
mem_d_we <= FALSE;
end
else
begin
case (op_s4)
I_ST:
begin
mem_d_w_addr <= reg_data_a_s4;
mem_d_w_data <= reg_data_b_s4;
mem_d_we <= TRUE;
end
default:
begin
mem_d_w_addr <= ZERO;
mem_d_w_data <= ZERO;
mem_d_we <= FALSE;
end
endcase
end
end
// stage 5 calc BL address
reg [DEPTH_I-1:0] bl_addr_s5;
always @(posedge clk)
begin
bl_addr_s5 <= mem_i_r_addr + BL_OFFSET;
end
// stage 5 execute branch
wire cond_true_s4;
assign cond_true_s4 = (reg_data_a_s4 != ZERO) ? TRUE : FALSE;
always @(posedge clk)
begin
if (reset == TRUE)
begin
mem_i_r_addr <= ZERO;
end
else
begin
// branch
if ((ENABLE_INT == TRUE) && (soft_reset == TRUE))
begin
mem_i_r_addr <= ZERO;
end
else if ((op_s4 == I_BA) || (op_s4 == I_BL) || ((op_s4 == I_BC) && (cond_true_s4)))
begin
mem_i_r_addr <= reg_data_b_s4;
end
else if ((ENABLE_WA == TRUE) && (op_s4 == I_WA))
begin
mem_i_r_addr <= mem_i_r_addr - wait_count_m1;
end
else
begin
mem_i_r_addr <= mem_i_r_addr + ONE;
end
end
end
// stage 5 delay
reg [4:0] op_s5;
reg [DEPTH_REG-1:0] reg_addr_d_s5;
reg [WIDTH_D-1:0] reg_data_a_s5;
reg [WIDTH_D-1:0] reg_data_b_s5;
always @(posedge clk)
begin
op_s5 <= op_s4;
reg_addr_d_s5 <= reg_addr_d_s4;
reg_data_a_s5 <= reg_data_a_s4;
reg_data_b_s5 <= reg_data_b_s4;
end
reg cond_true_s5;
generate
if (ENABLE_MVC == TRUE)
begin
always @(posedge clk)
begin
cond_true_s5 <= cond_true_s4;
end
end
endgenerate
// stage 6 compare
reg flag_cnz_s6;
reg flag_cnm_s6;
always @(posedge clk)
begin
if (reg_data_b_s5 == ZERO)
begin
flag_cnz_s6 <= FALSE;
end
else
begin
flag_cnz_s6 <= TRUE;
end
if (reg_data_b_s5[WIDTH_D-1] == 1'b0)
begin
flag_cnm_s6 <= TRUE;
end
else
begin
flag_cnm_s6 <= FALSE;
end
end
// stage 6 reg we
reg reg_we_s6;
wire stage6_reg_we_cond;
generate
if (ENABLE_MVC == TRUE)
begin
assign stage6_reg_we_cond = ((op_s5[4:3] != 2'b00) || (op_s5 == I_BL) || ((op_s5 == I_MVC) && (cond_true_s5 == TRUE)));
end
else
begin
assign stage6_reg_we_cond = ((op_s5[4:3] != 2'b00) || (op_s5 == I_BL));
end
endgenerate
always @(posedge clk)
begin
if (stage6_reg_we_cond)
begin
reg_we_s6 <= TRUE;
end
else
begin
reg_we_s6 <= FALSE;
end
end
// stage 6 delay
reg [4:0] op_s6;
reg [DEPTH_REG-1:0] reg_addr_d_s6;
reg [WIDTH_D-1:0] reg_data_a_s6;
reg [WIDTH_D-1:0] reg_data_b_s6;
reg [DEPTH_I-1:0] bl_addr_s6;
always @(posedge clk)
begin
op_s6 <= op_s5;
reg_addr_d_s6 <= reg_addr_d_s5;
reg_data_a_s6 <= reg_data_a_s5;
reg_data_b_s6 <= reg_data_b_s5;
bl_addr_s6 <= bl_addr_s5;
end
// stage 6 pre-execute
reg [WIDTH_D-1:0] reg_data_add_s6;
reg [WIDTH_D-1:0] reg_data_sub_s6;
reg [WIDTH_D-1:0] reg_data_and_s6;
reg [WIDTH_D-1:0] reg_data_or_s6;
reg [WIDTH_D-1:0] reg_data_xor_s6;
generate
if (FULL_PIPELINED_ALU == TRUE)
begin
always @(posedge clk)
begin
reg_data_add_s6 <= reg_data_a_s5 + reg_data_b_s5;
reg_data_sub_s6 <= reg_data_a_s5 - reg_data_b_s5;
reg_data_and_s6 <= reg_data_a_s5 & reg_data_b_s5;
reg_data_or_s6 <= reg_data_a_s5 | reg_data_b_s5;
reg_data_xor_s6 <= reg_data_a_s5 ^ reg_data_b_s5;
end
end
endgenerate
// stage 7 execute
reg [WIDTH_D-1:0] reg_data_w_s7;
always @(posedge clk)
begin
case (op_s6)
I_ADD:
begin
if (FULL_PIPELINED_ALU == TRUE)
begin
reg_data_w_s7 <= reg_data_add_s6;
end
else
begin
reg_data_w_s7 <= reg_data_a_s6 + reg_data_b_s6;
end
end
I_SUB:
begin
if (FULL_PIPELINED_ALU == TRUE)
begin
reg_data_w_s7 <= reg_data_sub_s6;
end
else
begin
reg_data_w_s7 <= reg_data_a_s6 - reg_data_b_s6;
end
end
I_AND:
begin
if (FULL_PIPELINED_ALU == TRUE)
begin
reg_data_w_s7 <= reg_data_and_s6;
end
else
begin
reg_data_w_s7 <= reg_data_a_s6 & reg_data_b_s6;
end
end
I_OR:
begin
if (FULL_PIPELINED_ALU == TRUE)
begin
reg_data_w_s7 <= reg_data_or_s6;
end
else
begin
reg_data_w_s7 <= reg_data_a_s6 | reg_data_b_s6;
end
end
I_XOR:
begin
if (FULL_PIPELINED_ALU == TRUE)
begin
reg_data_w_s7 <= reg_data_xor_s6;
end
else
begin
reg_data_w_s7 <= reg_data_a_s6 ^ reg_data_b_s6;
end
end
I_SR:
begin
reg_data_w_s7 <= sr_result_s6;
end
I_SL:
begin
reg_data_w_s7 <= sl_result_s6;
end
I_SRA:
begin
reg_data_w_s7 <= sra_result_s6;
end
I_CNZ:
begin
reg_data_w_s7 <= {WIDTH_D{flag_cnz_s6}};
end
I_CNM:
begin
reg_data_w_s7 <= {WIDTH_D{flag_cnm_s6}};
end
I_BL:
begin
reg_data_w_s7 <= bl_addr_s6;
end
I_MUL:
begin
if (ENABLE_MUL == TRUE)
begin
reg_data_w_s7 <= mul_result_s6;
end
else
begin
reg_data_w_s7 <= reg_data_b_s6;
end
end
I_LD:
begin
reg_data_w_s7 <= mem_d_r_data;
end
// I_MV, I_MVIL
default:
begin
reg_data_w_s7 <= reg_data_b_s6;
end
endcase
end
// stage 7 delay
reg [DEPTH_REG-1:0] reg_addr_d_s7;
reg reg_we_s7;
always @(posedge clk)
begin
reg_addr_d_s7 <= reg_addr_d_s6;
reg_we_s7 <= reg_we_s6;
end
wire [DEPTH_REG-1:0] reg_file_addr_r_a;
wire [DEPTH_REG-1:0] reg_file_addr_r_b;
generate
if (ENABLE_MVC == TRUE)
begin
assign reg_file_addr_r_a = reg_addr_a_s2;
assign reg_file_addr_r_b = reg_addr_b_s2;
end
else
begin
assign reg_file_addr_r_a = reg_d_s2[DEPTH_REG-1:0];
assign reg_file_addr_r_b = reg_a_s2[DEPTH_REG-1:0];
end
endgenerate
r2w1_port_ram
#(
.DATA_WIDTH (WIDTH_D),
.ADDR_WIDTH (DEPTH_REG),
.RAM_TYPE (REGFILE_RAM_TYPE)
)
reg_file
(
.clk (clk),
.addr_r_a (reg_file_addr_r_a),
.addr_r_b (reg_file_addr_r_b),
.addr_w (reg_addr_d_s7),
.data_in (reg_data_w_s7),
.we (reg_we_s7),
.data_out_a (reg_data_a_s_s3),
.data_out_b (reg_data_b_s_s3)
);
wire [WIDTH_D-1:0] mul_result_s6;
generate
if (ENABLE_MUL == TRUE)
begin
wire signed [WIDTH_D-1:0] mul_a_s3;
wire signed [WIDTH_D-1:0] mul_b_s3;
assign mul_a_s3 = reg_data_a_s_s3;
assign mul_b_s3 = (is_im_s3 == TRUE) ? $signed(reg_a_s3) : reg_data_b_s_s3;
delayed_mul
#(
.WIDTH_D (WIDTH_D)
)
delayed_mul_0
(
.clk (clk),
.a (mul_a_s3),
.b (mul_b_s3),
.out (mul_result_s6)
);
end
endgenerate
wire [WIDTH_D-1:0] sr_result_s6;
wire [WIDTH_D-1:0] sl_result_s6;
wire [WIDTH_D-1:0] sra_result_s6;
reg [WIDTH_D-1:0] sr_result_s6_reg;
reg [WIDTH_D-1:0] sl_result_s6_reg;
reg [WIDTH_D-1:0] sra_result_s6_reg;
generate
if (ENABLE_MULTI_BIT_SHIFT == TRUE)
begin
delayed_sr
#(
.WIDTH_D (WIDTH_D),
.SHIFT_BITS (SHIFT_BITS)
)
delayed_sr_0
(
.clk (clk),
.a (reg_data_a_s4),
.b (reg_data_b_s4[SHIFT_BITS-1:0]),
.out (sr_result_s6)
);
delayed_sl
#(
.WIDTH_D (WIDTH_D),
.SHIFT_BITS (SHIFT_BITS)
)
delayed_sl_0
(
.clk (clk),
.a (reg_data_a_s4),
.b (reg_data_b_s4[SHIFT_BITS-1:0]),
.out (sl_result_s6)
);
delayed_sra
#(
.WIDTH_D (WIDTH_D),
.SHIFT_BITS (SHIFT_BITS)
)
delayed_sra_0
(
.clk (clk),
.a (reg_data_a_s4),
.b (reg_data_b_s4[SHIFT_BITS-1:0]),
.out (sra_result_s6)
);
end
else
begin
always @(posedge clk)
begin
sr_result_s6_reg <= {1'b0, reg_data_a_s5[WIDTH_D-1:1]};
sl_result_s6_reg <= {reg_data_a_s5[WIDTH_D-2:0], 1'b0};
sra_result_s6_reg <= {reg_data_a_s5[WIDTH_D-1], reg_data_a_s5[WIDTH_D-1:1]};
end
assign sr_result_s6 = sr_result_s6_reg;
assign sl_result_s6 = sl_result_s6_reg;
assign sra_result_s6 = sra_result_s6_reg;
end
endgenerate
endmodule
module delayed_mul
#(
parameter WIDTH_D = 16
)
(
input clk,
input signed [WIDTH_D-1:0] a,
input signed [WIDTH_D-1:0] b,
output reg signed [WIDTH_D-1:0] out
);
reg signed [WIDTH_D-1:0] sa;
reg signed [WIDTH_D-1:0] sb;
reg signed [WIDTH_D-1:0] out1;
always @(posedge clk)
begin
sa <= a;
sb <= b;
out1 <= sa * sb;
out <= out1;
end
endmodule
module delayed_sr
#(
parameter WIDTH_D = 16,
parameter SHIFT_BITS = 4
)
(
input clk,
input [WIDTH_D-1:0] a,
input [SHIFT_BITS-1:0] b,
output reg [WIDTH_D-1:0] out
);
reg [WIDTH_D-1:0] sa;
reg [SHIFT_BITS-1:0] sb;
always @(posedge clk)
begin
sa <= a;
sb <= b;
out <= sa >> sb;
end
endmodule
module delayed_sl
#(
parameter WIDTH_D = 16,
parameter SHIFT_BITS = 4
)
(
input clk,
input [WIDTH_D-1:0] a,
input [SHIFT_BITS-1:0] b,
output reg [WIDTH_D-1:0] out
);
reg [WIDTH_D-1:0] sa;
reg [SHIFT_BITS-1:0] sb;
always @(posedge clk)
begin
sa <= a;
sb <= b;
out <= sa << sb;
end
endmodule
module delayed_sra
#(
parameter WIDTH_D = 16,
parameter SHIFT_BITS = 4
)
(
input clk,
input [WIDTH_D-1:0] a,
input [SHIFT_BITS-1:0] b,
output reg [WIDTH_D-1:0] out
);
reg signed [WIDTH_D-1:0] sa;
reg [SHIFT_BITS-1:0] sb;
always @(posedge clk)
begin
sa <= a;
sb <= b;
out <= sa >>> sb;
end
endmodule