独自CPUを自作する(メモリ操作の速いアーキテクチャ編)
【更新履歴】
2023/12/15 AMD (Xilinx) Kria KV260, KR260に対応しました。
2018/10/03 DE0-CVのUARTのピン配置を変更しました。以前に使用された方は繋ぎ変えてください。
I2Cバスに対応しました。
TinyFPGA BXボードに対応しました。
2017/11/27 アドレッシング・モードの仕様を修正。IN,OUT命令を削除(MMIOに移行)。SC1-SoCの情報を追加。
2016/12/23 SIMD命令実装のパッチを追加(SIMD対応版解説ページ)
2016/06/06 マルチコア実装のテストを追加
2016/05/29 parameterの記述を変更。簡易アセンブラにラベル機能を追加。BeMicro CV A9、MAX10-FB基板、Terasic DE0-CV、iCE40HX-8K(開発環境: IceStorm)用のプロジェクトを追加
2016/02/07 LOOP命令の追加、回路規模を抑えるための仕様変更、メモリ書き換え条件のバグの修正。
2015/12/27 新規公開
メモリアクセスの方法に工夫をして性能を向上させるアーキテクチャを考えてみます。
このアーキテクチャについて
前回作ったCPUは極力シンプルな設計を目指したもので、作りやすさ、理解しやすさを優先させたものでした。
非パイプライン実行であるため、アセンブラでプログラムが組みやすく、また、レジスタ上の値の演算は1サイクルで行えるためスピードも普通に出るのですが、メモリ上のデータのロード、ストアにまるまる3サイクルかかるので、大量のデータに対して単純な演算を繰り返すようなプログラムにおいてはメモリ操作にかかるコストが無視できないものになっていました。
例えば、以下のプログラムを考えてみます。
{
d[id] = a[ia] + b[ib];
id += dd;
ia += da;
ib += db;
}
このプログラムのループ内部を前回のCPU(通常のロード・ストア型アーキテクチャ)のアセンブラで書いた場合、以下のようになり、合計13サイクルかかります。
load r1 = mem[r4]; // 3
add r2 = r0 + r1; // 1
store mem[r5] = r2; // 3
add r3 = r3 + r6; // 1
add r4 = r4 + r7; // 1
add r5 = r5 + r8; // 1
これを今回のアーキテクチャでは以下のように1サイクルで行えるようにします。
これを実現するためには、1サイクルあたりにメモリから2回の読み込みと1回の書き込みが行える必要があります。
そのために、読み込みと書き込みを同時にできるデュアルポートRAMを2ライン使用し、両方のRAMに同じ値のコピーを書き込むようにして、2つのRead Addressと1つのWrite Addressを同時に処理できるようにしました。
また、これらのアドレスを格納するために3つの専用レジスタ(d_addr, a_addr, b_addr)を用意し、演算の実行後にオペランドで与えた3つのレジスタの値をアドレスレジスタに加算する、自動アドレス・インクリメントの機能を付けました。
基本的な命令セット・アーキテクチャは以下のようになっています。

メモリ操作の方法
7-12bit目のAddressing ModeでオペランドD, A, Bそれぞれについて、レジスタまたはメモリの処理方法を指定します。
Addressing Mode=0の場合はオペランドの下位4bitをレジスタ番号とみなし、そのレジスタの値を使用して演算を行います。
A, Bにおいてはオペランドの最上位ビットが1の時、下位5bitをSignedの即値として扱います。
Addressing Mode=1,2,3はメモリに対する操作になります。
SC1-CPUでは内部的なアドレス・レジスタ(d_addr, a_addr, b_addr)を持っており、オペランドのレジスタの値をこれにセットしたり加算したりしてメモリにアクセスします。
Addressing Mode=1ではオペランドで指定されたレジスタの値をアドレスとして使用して命令を実行します。この値はアドレス・レジスタに保存されます。
Addressing Mode=2ではアドレス・レジスタに保存されているアドレスを使って命令を実行し、実行後にオペランドで指定されたレジスタの値をアドレス・レジスタに加算します。これによりメモリ上の連続領域に高速にアクセスできます。
Addressing Mode=3ではオペランドを6bit Signedの即値とみなし、その値をアドレス・レジスタの値に一時的に加算したアドレスを使って命令を実行します。アドレス・レジスタ自体は変更されません。命令毎にオフセット値を変化させてアクセスできるので構造体などに高速にアクセスできます。
数値演算以外にも多くの命令がこのアドレッシング・モードに対応しています。
演算を行わずアドレスレジスタのみを操作したい場合にはNOP命令でAddressing Modeをセットして使用します。これは主にAddressing Mode=2,3の前段階で使用します。
このような仕組みにより、2系統のメモリ読み込み、演算、1系統の書き込み、3つのアドレスのインクリメントを1命令で行い、これを1サイクルで連続して実行できるアーキテクチャを実現しています。
前回のCPUと比較して分かるとおり、同じスカラプロセッサでもアーキテクチャの違いだけで10倍以上も実効速度に差が出る場合があります。
アセンブリ言語
基本的なアセンブリ言語表現は以下のようになります。
opcode(operand_d, operand_a, operand_b, addressing_mode_d, addressing_mode_a, addressing_mode_b);
ハードウェア・ループ命令
メモリ上の連続データを処理する操作を考えてみます。
mem[d_addr] = mem[a_addr] + mem[b_addr]; (d_addr+=R8; a_addr+=R9; b_addr+=R10;)
この処理をN回繰り返すプログラムを通常の条件分岐を使ったループで書くと以下のようになります。
R11: 1
R12: ループカウンタ用。初期値0。
R13: ループ回数: N
として、
add(12,12,11, 0,0,0); // ループカウンタをインクリメント:R12 = R12 + R11;
cgt(13,12, 0,0); // 比較命令:if (R13 > R12) R1 = 0xffffffff; else R1 = 0;
bc(-3); // 条件分岐命令:if (R1 != 0) PC += -3;
nop(0,0,0,0,0,0); // 分岐命令の遅延スロット1サイクル目
nop(0,0,0,0,0,0); // 分岐命令の遅延スロット2サイクル目
nop(0,0,0,0,0,0); // 分岐命令の遅延スロット3サイクル目(ここまで実行してから分岐先に飛ぶ)
このように、ループさせたい命令は1個だけなのに、ループさせるためだけのコードに1回のループあたり6サイクルが余分に必要となります。
これではあまりに実効効率が悪いのでループ・アンローリングを行って次のように書けばループ処理に必要なコストが相対的に減少しますが、コード容量が大きくなる副作用があります。
R13: N/16 として、
add(8,9,10, 2,2,2);
add(8,9,10, 2,2,2);
add(8,9,10, 2,2,2);
add(8,9,10, 2,2,2);
add(8,9,10, 2,2,2);
add(8,9,10, 2,2,2);
add(8,9,10, 2,2,2);
add(8,9,10, 2,2,2);
add(8,9,10, 2,2,2);
add(8,9,10, 2,2,2);
add(8,9,10, 2,2,2);
add(8,9,10, 2,2,2);
add(8,9,10, 2,2,2);
add(8,9,10, 2,2,2);
add(8,9,10, 2,2,2);
add(12,12,11, 0,0,0);
cgt(13,12, 0,0);
bc(-18);
nop(0,0,0,0,0,0);
nop(0,0,0,0,0,0);
nop(0,0,0,0,0,0);
そこで、単純なループ処理をハードウェア的に行うためのLOOP命令を作りました。
これは、指定した範囲の命令を指定回数繰り返す機能を持った命令です。パラメーターはR3,R4,R5で与えます。
R3: ループ回数: N-1
R4: ループ終了位置オフセット: 4 (loop命令の4サイクル後の命令で分岐実行)
R5: 分岐先オフセット: 0 (PC = PC + 0; つまり同じ命令を繰り返す)
として、
nop(0,0,0,0,0,0); // 命令配置制約により3サイクルのウェイトが必要(4命令以上からなるループでは不要。)
nop(0,0,0,0,0,0);
nop(0,0,0,0,0,0);
add(8,9,10, 2,2,2);
LOOP命令を使用するとこのように書けます。ループ実行前にパラメーターのセットやウェイト時間が必要ですが、ループ処理自体は最後のadd命令に対してのみ行われ、1サイクルで連続実行されます。つまりループ回数が十分に大きければループ処理にかかるコストはほぼゼロとなります。
命令セット・アーキテクチャ・リファレンス
オペランド
operand_d (6bit): オペランドDoperand_a (6bit): オペランドA
operand_b (6bit): オペランドB
im (16bit): 即値
am_d (2bit): オペランドDのアドレッシング・モード
am_a (2bit): オペランドAのアドレッシング・モード
am_b (2bit): オペランドBのアドレッシング・モード
アドレッシング・モード
(am:アドレッシング・モード, o:オペランド, addr:命令実行時に使用されるアドレス, addr_s:内部的に保存されるアドレス)am:0
対象はレジスタ。
オペランドの最上位ビットが0の時、オペランドを4bitのレジスタ番号とみなして処理する。
operand = reg[o]
オペランドA,Bにおいて、オペランドの最上位ビットが1の時、オペランドを5bit Signedの即値として処理する。
operand = o
am:1
対象はメモリ。アドレスに指定レジスタの値を代入して命令を実行。そのアドレスは内部的に保存される。
operand = mem[addr]; addr = reg[o]; addr_s = reg[o];
am:2
対象はメモリ。保存されているアドレスを使用して命令を実行し、実行後に指定レジスタの値をアドレスに加算して保存。(post increment)
operand = mem[addr]; addr = addr_s; addr_s = addr_s + reg[o];
am:3
対象はメモリ。アドレスに即値を一時的に加算(オフセット値)して命令を実行。保存されているアドレスは変化しない。
operand = mem[addr]; addr = addr_s + o; addr_s = addr_s;
レジスタ
専用レジスタ:PC: プログラムカウンタ
d_addr: オペランドDのメモリのアドレス・レジスタ
a_addr: オペランドAのメモリのアドレス・レジスタ
b_addr: オペランドBのメモリのアドレス・レジスタ
汎用レジスタ:
R0 〜 R15
(R0 〜 R5は特定命令で使用される)
R0: MVI, BA
R1: CEQ, CGT, CGTA
R2: BL
R3~5: LOOP
各命令の解説
- ADD
解説:加算
アセンブリ:add(reg_d, reg_a, reg_b, am_d, am_a, am_b)
機能:D = A + B;
- SUB
解説:減算
アセンブリ:sub(reg_d, reg_a, reg_b, am_d, am_a, am_b)
機能:D = A - B;
- AND
解説:論理AND
アセンブリ:and(reg_d, reg_a, reg_b, am_d, am_a, am_b)
機能:D = A & B;
- OR
解説:論理OR
アセンブリ:or(reg_d, reg_a, reg_b, am_d, am_a, am_b)
機能:D = A | B;
- XOR
解説:論理XOR
アセンブリ:xor(reg_d, reg_a, reg_b, am_d, am_a, am_b)
機能:D = A ^ B;
- NOT
解説:論理NOT
アセンブリ:not(reg_d, reg_a, am_d, am_a)
機能:D = ~A;
- SR
解説:Shift Right。論理右シフト
アセンブリ:sr(reg_d, reg_a, reg_b, am_d, am_a, am_b)
機能:D = A >> B;
- SL
解説:Shift Left。論理左シフト
アセンブリ:sl(reg_d, reg_a, reg_b, am_d, am_a, am_b)
機能:D = A << B;
- SRA
解説:Shift Right Arithmetic。算術右シフト
アセンブリ:sra(reg_d, reg_a, reg_b, am_d, am_a, am_b)
機能:D = A >>> B;
- MUL
解説:乗算
アセンブリ:mul(reg_d, reg_a, reg_b, am_d, am_a, am_b)
機能:D = A * B;
- HALT
解説:プログラム実行停止。Resume信号で再開される。
アセンブリ:halt()
機能:if (Resume signal) {PC = PC + 1;}
else {PC = PC;} - NOP
解説:何もしない。ただし、アドレッシング・モードに0以外を指定すればアドレス操作だけを行うことが可能。アドレス操作も行わない場合はam_d, am_a, am_bを0にしなければいけない。
アセンブリ:nop(reg_d, reg_a, reg_b, am_d, am_a, am_b)
機能:None
- MV
解説:Move。もし(R1 != 0)ならばDにAを代入。
アセンブリ:mv(reg_d, reg_a, am_d, am_a)
機能:if (R1 != 0) {D = A;}
- MVI
解説:Move Immediate。16bit即値をR0に代入。上位16bitは0
アセンブリ:mvi(im)
機能:R0 = im
- MVIH
解説:Move Immediate High。16bit即値をR0の上位16bitに代入。
アセンブリ:mvih(im)
機能:R0 = (R0 & 0xffff) | (im << 16)
- CEQ
解説:Compare Equal。もし(A == B)ならばR1 = 0xffffffff、それ以外ならR1 = 0
アセンブリ:ceq(reg_a, reg_b, am_a, am_b)
機能:if (A == B) {R1 = 0xffffffff;} else {R1 = 0;}
- CGT
解説:Compare Greater Than。もし(A > B)ならばR1 = 0xffffffff、それ以外ならR1 = 0
アセンブリ:cgt(reg_a, reg_b, am_a, am_b)
機能:if (A > B) {R1 = 0xffffffff;} else {R1 = 0;}
- CGTA
解説:Compare Greater Than Arithmetic。A、Bをsignedとして扱い、もし(A > B)ならばR1 = 0xffffffff、それ以外ならR1 = 0
アセンブリ:cgta(reg_a, reg_b, am_a, am_b)
機能:if (A(signed) > B(signed)) {R1 = 0xffffffff;} else {R1 = 0;}
- BC
解説:Branch Conditional。もし(R1 != 0)なら現在のPCにR0を加算した命令アドレスに分岐する。それ以外なら次の命令に進む。
アセンブリ:bc()
機能:if (R1 != 0) {PC += R0;}
- BL
解説:Branch and Link。現在のPC+ディレイ・スロット(3)+1をR2にコピーし、現在のPCにR0を加算した命令アドレスに分岐する。このリンク・アドレスを用いてリターン(BA)した場合、この命令のディレイ・スロットを飛び越してその次の命令に戻ってくる。
アセンブリ:bl()
機能:{R2 = PC + 1 + DelaySlot(3); PC += R0;}
- BA
解説:Branch Absolute。R0の値の命令アドレスにジャンプする。
アセンブリ:ba()
機能:PC = R0
- LOOP
解説:ループ命令。指定範囲の命令を指定回数繰り返し実行する。
ループ回数:(R3 + 1)
ループ終了位置オフセット:R4 (この命令のPC + R4の命令を実行後にジャンプする)
ジャンプ先オフセット:R5(ループ終了位置のPC + R5にジャンプ)
R4 >= 4, R5 <= 0 でなければならない。アセンブリ:loop()
機能:R3, R4, R5を内部レジスタにコピーし、ループ実行を予約する。
命令配置制約
- 分岐命令(BC,BL,BA)、HALTの後の3命令は遅延スロットとなる。分岐命令の後3ステップの命令はそのまま実行され、4サイクル後に分岐先の命令が実行される。条件分岐の有無に関わらず遅延スロットの命令は実行される。混乱を避けるため通常は遅延スロットにはNOPを置く場合が多い。
例:
bc(); // if (R1 != 0) PC += R0
nop(0,0,0,0,0,0);
nop(0,0,0,0,0,0);
nop(0,0,0,0,0,0); // この命令まで実行されてから分岐先に飛ぶ
- アドレッシング・モードがSet(1)もしくはIncrement(2)の命令で参照されるレジスタを操作する命令は、その命令の3サイクル以上前に置かなければいけない。
例:
mvi(16); // MVIレジスタR0に値16を代入
nop(0,0,0,0,0,0); // 2サイクル待つ
nop(0,0,0,0,0,0);
nop(0,0,0, 1,1,1); // d_addr, a_addr, b_addrにR0の値を代入
- 書き込み先がメモリの場合、書き換え後の値が読み込み可能となるのは3サイクル後である。ゆえにデータ依存性のある操作を連続して行う場合、2サイクル以上他の命令を挟まなければならない。
例:
R6=1; d_addr=8; a_addr=8; であるとして、
add(0,0,6, 3,3,0); // mem[8] = mem[8] + 1;
nop(0,0,0,0,0,0); // 2サイクル待つ
nop(0,0,0,0,0,0); // ここにはNOP以外に無関係な他の命令を入れても良い
add(0,0,6, 3,3,0); // mem[8] = mem[8] + 1;
- 無条件のMV命令はないのでADDで0を加算する操作等で代用する。
例:
mvi(0); // r0 = 0
add(8,0,0, 0,0,0); // r8 = r0 + r0 = 0
mvi(1); // r0 = 1
add(9,0,8, 0,0,0); // r9 = r0 + r8 = 1
- LOOP命令のループ終了位置オフセットはLOOP命令の4サイクル後以降に設定しなければいけない。
例:
mvi(0); // r0 = 0
add(8,0,0, 0,0,0); // r8 = r0 + r0 = 0
mvi(7); // r0 = 7
add(3,0,8, 0,0,0); // r3 = r0 + r8 = 7 : ループ回数 = 7 + 1
mvi(3); // r0 = 4
add(4,0,8, 0,0,0); // r4 = r0 + r8 = 4 : ループ終了位置はLOOP命令の4サイクル後
add(5,8,8, 0,0,0); // r5 = r8 + r8 = 0 : ループ終了位置からのジャンプ先オフセットは0 (同じ命令を繰り返す)
loop(); // ループ実行(予約)
nop(0,0,0,0,0,0); // ウェイト(他の無関係な命令を置いても良い)
nop(0,0,0,0,0,0);
nop(0,0,0,0,0,0);
add(9,9,9, 2,2,2); // mem[d]=mem[a]+mem[b]; d+=r9; a+=r9; b+=r9; // この命令が8回繰り返される
- LOOP命令を使ったループの中の最後の命令が遅延スロット内の命令であってはいけない。(最後がBL命令+3xNOPの場合など)その後にNOPかその他の命令を1つ配置すること。
- LOOP命令はネスト不可だが通常の条件分岐を使ったループの中にLOOP命令のループを置いたり、LOOP命令のループの中に通常の条件分岐を使ったループを置くことは可能。
- 遅延スロットに置かれた命令は複数回実行される場合がある。(ループの終了地点で使われた場合など)遅延スロットを利用する場合はそのことを考慮する必要がある。
Application Binary Interface (ABI)
- スタック・ポインター
R15はスタック・ポインター格納用に予約する。
プログラムは開始時にデータメモリの最終アドレスをスタック・ポインターにセットしなければならない。
スタックは最終アドレスから開始アドレスに向かって成長させる。
関数はスタック・ポインターを呼び出し時点の値に復元してからリターンしなければならない。 - リンク・レジスターの保存
関数は入り口でリンク・レジスター(R2)の値を保存し、リターンする前にこれを復元しなければならない。リンク・レジスターはBL命令実行時に変更される。
- レジスター割り当て
R6からR9までは関数の引数や戻り値として使用する。順序は引数リストの左から、番号の若い順に割り当てる。揮発性(復元責任は呼び出し側)。
R10からR11は揮発性の汎用レジスター。
R12からR14は非揮発性(呼び出された側が復元責任を持つ)の汎用レジスター。
SC1-SoCについて
SC1-CPUにビデオ・コントローラー、オーディオ・インターフェイス、UART、スクラッチパッド・メモリ、LEDなど周辺I/Oを接続してFPGAで1チップで実装したシステムです。
現在のプロジェクトはこの構成になっています。
周辺デバイスはSC1-CPUからMMIOで制御する形になっています。(メモリにアクセスするのと同じようにデバイスの制御レジスタのアドレスに対して書き込み、読み込みを行います。)
現時点でソフトウェア・FMシンセサイザーやグラフィック出力のデモなどが動作し汎用的に利用できることを確認しています。
ターゲットボードについて
このプロジェクトは以下のFPGAボードに対応しています。
Terasic DE0-CV
BeMicro CV A9
TinyFPGA BX
以下のボードでは周辺I/OはLEDとUARTのみの対応です。
BeMicro Max 10
MAX10-FB基板(FPGA電子工作スーパーキット付録基板)
iCE40HX-8K(開発環境: IceStorm)
I/O電圧のジャンパ設定について
●BeMicro Max 10の場合
BeMicro Max 10ではボードのI/O電圧を3.3Vに設定することを前提にしています。
BeMicro Max 10 Getting Started User Guide(もしくはこちら)のp.5を参照してVCCIO選択ジャンパ (J1,J9)が3.3V側に設定されていることを確認してください。
●MAX10-FB基板の場合
I/O電圧を3.3Vに設定することを前提にしています。
書籍の標準設定では3.3V設定になっています。
●BeMicro CV A9の場合
BeMicro CV A9ではボードのI/O電圧を3.3Vに設定することを前提にしています。
BeMicro CV A9 Hardware Reference Guide
のp.23を参照してVCCIO選択ジャンパ (J11)のpin 1とpin 2が接続されていることを確認してください。
論理合成・実行方法
ここではFPGAのビットストリーム転送までを解説します。
SC1-CPU用のプログラムを動かすためには後述のUARTの設定が必要です。
ダウンロード:sc1_cpu.tar.gz
●AMD (Xilinx) Kria KV260, KR260の場合
Vivado, Vitis 2023.2のStand Aloneモードで合成、実行します。詳しくは sc1_cpu/kv260/readme.txt を参照してください。
●Terasic DE0-CV、BeMicro Max 10、BeMicro CV A9の場合
Quartus Primeは「AlteraのFPGA開発ツール「Quartus Prime」をUbuntuにインストールする」の方法でインストールしているものとします。
ターミナルで、
tar xzf sc1_cpu.tar.gz
Quartus Ver.15.0以上 でプロジェクトファイルを開いて「Start Compilation」、「Programmer」で転送して実行します。
プロジェクトファイル:
Terasic DE0-CV: sc1_cpu/de0-cv/de0-cv_start.qpf
BeMicro Max 10: sc1_cpu/bemicro_max10/bemicro_max10_start.qpf
BeMicro CV A9: sc1_cpu/bemicro_cva9/bemicro_cva9_start.qpf
●MAX10-FB基板 の場合
MAX10-JB基板は初期状態ではWindows環境でしか使用できない設定になっているため、まず「FPGA電子工作スーパーキット・サポートサイト」に書かれている方法でアップデートしてLinuxに対応させる必要があります。(もしくは書き込み時のみWindowsを使います。)
Quartus Ver.15.0以上 でプロジェクトファイル sc1_cpu/max10fb/max10fb_start.qpfを開いて「Start Compilation」、「Programmer」で転送して実行します。
●iCE40HX-8K(開発環境: IceStorm)の場合
オープンソースの開発環境IceStormでコンパイル、転送します。
詳しくは sc1_cpu/ice40hx8k/readme_icestorm.txt を参照してください。
Raspberry Pi、PCとの接続
Raspberry Pi、もしくはUSBシリアルケーブルを接続したPCからFPGAにUARTで接続して、プログラムの転送、実行を行えるようにしました。
- このプロジェクトにおける各ボードごとのUARTピン配置
ボード UART_TXD UART_RXD GND Raspberry Pi 8番ピン 10番ピン 6番ピン DE0-CV GPIO-0の35番ピン GPIO-0の37番ピン GPIO-0の12または30番ピン Bemicro Max10 GPIO_J4の35番ピン GPIO_J4の37番ピン GPIO_J4の33番ピン Bemicro CVA9 GPIO_J4の35番ピン GPIO_J4の37番ピン GPIO_J4の33番ピン Lattice iCE40HX-8K D16ピン(J2-35番ピン) C16ピン(J2-37番ピン) GND(J2-39番ピン) MAX10-FB基板 P140(CN2-8番ピン) P141(CN2-9番ピン) GND(CN2-20番ピン) TinyFPGA BX Pin_1 Pin_2 G - Raspberry Pi 3の場合
以下のように接続します。TXDとRXDはクロス接続となっていることに注意してください。
RPi RXD0 ---- FPGA UART_TXD
RPi TXD0 ---- FPGA UART_RXD
RPi GND ---- FPGA GND
参考:Raspberry Pi ピン配置図

写真と実際の配線は異なります。(仕様を変更しました。)
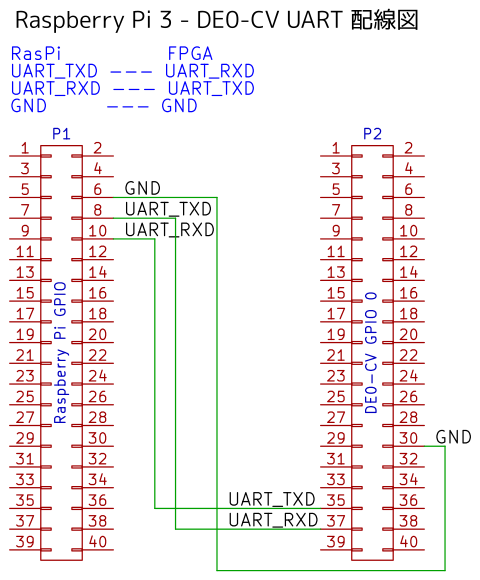
クリックして拡大
Raspberry PiのUART端子をRaspberry Pi側から外部デバイスに向けて使用できるように設定します。
ターミナルで、
sudo raspi-config
Interfacing Options: Serial: Would you like a login shell to be accessible over serial?: No
Would you like the serial port hardware to be enabled?: Yes
設定を保存、raspi-configを閉じて、
sudo rnano /boot/config.txt
以下の設定をファイル末尾に追加して保存します。
dtoverlay=pi3-miniuart-bt
SC1-CPUのプログラム転送ツールなどでデバイス名の指定を省略できるようにする設定です。
rnano ~/.bashrc
ファイル末尾に追加export UART_DEVICE=/dev/ttyAMA0
sudo reboot
- PCの場合
PCに接続する場合、USBシリアルケーブルが別途必要です。(FTDI TTL-232R-3V3など。必ずTTL 3.3V 仕様のものを使ってください。電圧が異なるものを使うと最悪FPGAが壊れます。)
FTDI TTL-232R-3V3 にもVCC 5Vのピンが1本あるので、これを間違えて接続しないよう注意してください。
これを以下のように接続します。
TXDとRXDはクロス接続となっていることに注意してください。
シリアルケーブル RXD ---- FPGA UART_TXD
シリアルケーブル TXD ---- FPGA UART_RXD
シリアルケーブル GND ---- FPGA GND
FTDI TTL-232R-3V3の場合、以下のようにudevのパーミッションを設定します。他機種の場合は、idVendor、idProductを読み替えてください。(USBで接続してからlsusbコマンドを打つと調べられます。ID idVendor:idProductの順です。)
sudo rnano /etc/udev/rules.d/99-ft232.rulesKERNEL=="ttyUSB*", ATTRS{idVendor}=="0403", ATTRS{idProduct}=="6001", GROUP="plugdev", MODE="0666"
sudo udevadm control --reload-rules
rnano ~/.bashrc
ファイル末尾に追加export UART_DEVICE=/dev/ttyUSB0
その他のI/Oの接続
- DE0-CV版
DE0-CV版では、音声出力インターフェイスを接続します。「DE0-CV向けオーディオ・アダプタの製作」と同じものです。DE0-CVのGPIOとの接続は単線のジャンパーワイヤで行います。
- BeMicro CV A9版
BeMicro CV A9版では、「映像・音声・コントローラー・インターフェースの製作」の拡張ボードを接続します。
- TinyFPGA BX版
TinyFPGA BX版では、以下の回路をブレッドボード等で実装します。UART、VGAモニタ出力(1024x768モード)、音声出力に対応し、sc1_cpu/asm/MiniSynth.java が動作します。
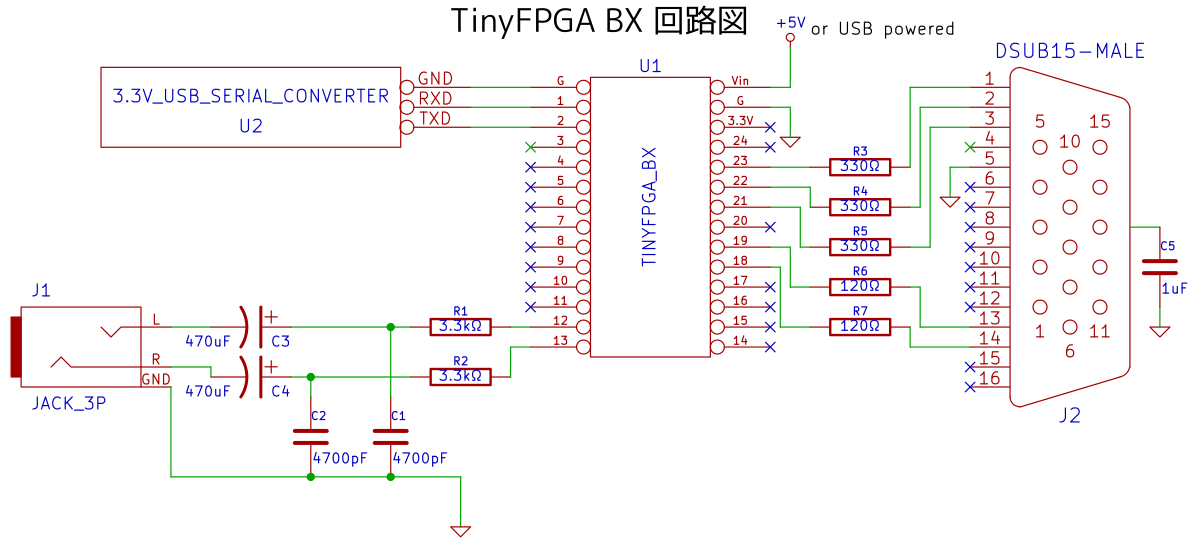
クリックして拡大
-
DE0-CV, BeMicro Max10, TinyFPGA BX版はI2Cバスに対応しています。以下のようにデバイスを接続して使用します。
TinyFPGA BX版は sc1_cpu/tinyfpgabx/top.v の「//`define USE_TIMER」と「//`define USE_I2C」をアンコメントしてから合成すると有効になります。
sc1_cpu/asm/Examples.java の example_i2c() でテストできます。
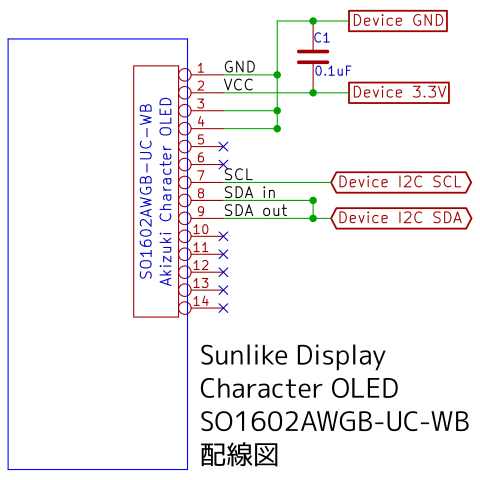
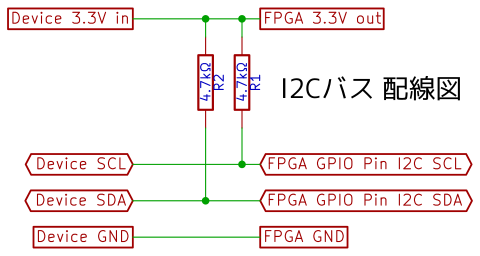
ボード I2C SCL I2C SDA GND 3.3V DE0-CV GPIO-0の36番ピン GPIO-0の38番ピン GPIO-0の12または30番ピン GPIO-0の29番ピン BeMicro Max10 J4の4番ピン(直結)
プルアップ抵抗は
内蔵なので不要ですJ4の3番ピン(直結)
プルアップ抵抗は
内蔵なので不要ですJ4の7番ピン J4の1番ピン TinyFPGA BX Pin_15 Pin_14 G 3.3V
UART経由でのプログラムの転送、実行
上記のように設定したRaspberry PiまたはPCで、
cd sc1_cpu
make run
これでツールのコンパイル、プログラムのコンパイル、転送、実行が行われます。
デフォルトではLEDが点滅するサンプル・プログラムが起動するようになっています。
サンプルプログラム
デフォルトで起動するLED点滅プログラムです。カウンターの上位の値をLEDで2進数表示します。
lib_set_im32(LED_ADDRESS);
lib_simple_mv(R8, SP_REG_MVI);
as_add(R6,reg_im(0),reg_im(0), AM_REG,AM_REG,AM_REG); // r6 = 0
lib_set_im(19); // r0 = 19 (19 on the real machine, 0 on the simulation)
lib_simple_mv(R7, SP_REG_MVI);
// loop
label("L_0");
as_sr(R8,R6,R7, AM_SET,AM_REG,AM_REG); // mem[LED_ADDRESS] = r6 >> r7
as_add(R6,R6,reg_im(1), AM_REG,AM_REG,AM_REG); // r6++
lib_ba("L_0"); // goto L_0
Verilogシミュレータ「Icarus Verilog」でのシミュレーション
「Icarus Verilog」を使えばFPGAボードがなくても開発・シミュレーションを行うことができます。
「Icarus Verilogコンパイラを使う」の方法で iverilog と gtkwave をインストールし、
cd sc1_cpu/testbench
make run
でシミュレーションできます。出力された wave.vcd を gtkwave で開いて画面左側の信号リストから見たい信号を右側の波形画面へドラッグ&ドロップすれば信号波形を観察できます。
デフォルト以外のプログラムをシミュレーションする場合は、
cd sc1_cpu
make
で出力された default_code_tb.txt, default_data_tb.txt の内容を
sc1_cpu/testbench/testbench.v の
「// program start here --------」「// data start here --------」と書かれた場所にコピペしてから実行してください。
このCPUでプログラミングする方法
sc1_cpu/asm 以下にJava上で動作する簡易アセンブラが入っています。
実行にはOpenJDK 8.0以上のインストールが必要です。
AsmLibクラスを継承したクラスを作り、init()で初期化設定、program()にプログラム、data()にデータを記述します。AsmTop.javaも修正します。
sc1_cpuディレクトリに移動して make を実行するとプログラム・バイナリが出力されます。
PCとFPGAをUARTで接続し、 make run を実行するとバイナリがFPGAに転送されて実行されます。
詳しくはExamples.javaのソースコードを参照してください。
SC1-SoCからのUART出力を使用するプログラムでは、あらかじめ別のターミナル上で、
cd sc1_cpu/tools
./reciever
を実行してください。
マルチコア実装のテスト
※旧バージョンの情報。現在アップデートに伴い改修中です。
旧バージョンで試してみたい方はこちらをどうぞ:sc1_cpu_ver1.tar.gz
複数のSC1-CPUコアを実装するテストです。DE0-CVとBemicroCV A9に対応しています。
DE0-CV:10コア実装して各コアに一つずつLEDを接続します。
BemicroCV A9:80コア実装して各コアの出力全てのxorを取った値で一つのLEDを点滅させます。
通常版のソースコードにパッチを当ててから合成します。詳しくは sc1_cpu/patches/readme_patches.txt を参照してください。
SIMD命令実装のパッチ
※旧バージョンの情報。現在アップデートに伴い改修中です。
8bit整数のSIMD命令を追加するパッチです。
v8mv, v8ceq, v8cgt, v8cgta, v8add, v8sub, v8mul, v8sr, v8sl, v8sra が追加されます。
レジスタを8bitに区切り、各要素ごとに演算を行います。
SC1-CPUをWIDTH_D = 32, WIDTH_REG = 32でインスタンス化した場合は32bit / 8bit = 4要素を同時に処理できます。
256bitでインスタンス化した場合は32要素を同時に処理できます。(スカラ演算は256bit整数になります。)
通常版のソースコードにパッチを当ててから合成します。詳しくは sc1_cpu/patches/readme_patches.txt を参照してください。
SIMD対応版解説ページ
ソースコード
これらのソースコードはBSD 2-Clauseライセンスで公開します。
sc1_cpu.v : CPU本体
Copyright (c) 2015 miya
All rights reserved.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED.
IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
module sc1_cpu
#(
parameter WIDTH_I = 32,
parameter WIDTH_D = 32,
parameter DEPTH_I = 8,
parameter DEPTH_D = 8,
parameter DEPTH_REG = 4
)
(
input wire clk,
input wire reset,
input wire resume,
input wire [WIDTH_I-1:0] mem_i_r,
output reg [DEPTH_I-1:0] mem_i_addr_r,
input wire [WIDTH_D-1:0] mem_d_r_a,
input wire [WIDTH_D-1:0] mem_d_r_b,
output reg [WIDTH_D-1:0] mem_d_w,
output reg [DEPTH_D-1:0] mem_d_addr_w,
output reg [DEPTH_D-1:0] mem_d_addr_r_a,
output reg [DEPTH_D-1:0] mem_d_addr_r_b,
output reg mem_d_we,
output reg stopped
);
localparam SP_REG_MVI = 4'd0;
localparam SP_REG_BA = 4'd0;
localparam SP_REG_CP = 4'd1;
localparam SP_REG_LINK = 4'd2;
localparam SP_REG_LOOP_COUNTER = 4'd3;
localparam SP_REG_LOOP_END = 4'd4;
localparam SP_REG_LOOP_SPAN = 4'd5;
// opcode
// special type
localparam I_HALT = 7'h00;
localparam I_NOP = 7'h01;
localparam I_MV = 7'h02;
localparam I_MVI = 7'h03;
localparam I_MVIH = 7'h04;
localparam I_CEQ = 7'h05;
localparam I_CGT = 7'h06;
localparam I_CGTA = 7'h07;
localparam I_BC = 7'h08;
localparam I_BL = 7'h09;
localparam I_BA = 7'h0a;
localparam I_LOOP = 7'h0b;
// normal type
localparam I_ADD = 7'h40;
localparam I_SUB = 7'h41;
localparam I_AND = 7'h42;
localparam I_OR = 7'h43;
localparam I_XOR = 7'h44;
localparam I_NOT = 7'h45;
localparam I_SR = 7'h46;
localparam I_SL = 7'h47;
localparam I_SRA = 7'h48;
localparam I_MUL = 7'h49;
localparam TRUE = 1'b1;
localparam FALSE = 1'b0;
localparam ONE = 1'd1;
localparam ZERO = 1'd0;
localparam FFFF = {WIDTH_D{1'b1}};
localparam ADDR_MODE_0 = 2'd0;
localparam ADDR_MODE_1 = 2'd1;
localparam ADDR_MODE_2 = 2'd2;
localparam ADDR_MODE_3 = 2'd3;
localparam DELAY_SLOT = 2'd3;
localparam DELAY_SLOT_P1 = 3'd4;
localparam OPERAND_BITS = 6;
localparam REG_IM_BITS = 5;
localparam NOP_OP = ONE;
reg resume_d1;
wire resume_pulse;
wire mem_d_we_sig;
reg [DEPTH_D-1:0] mem_d_addr_w_d0;
reg [DEPTH_D-1:0] mem_d_addr_w_d1;
reg [DEPTH_D-1:0] mem_d_addr_w_s_d0;
reg [DEPTH_D-1:0] mem_d_addr_r_a_s;
reg [DEPTH_D-1:0] mem_d_addr_r_b_s;
reg [DEPTH_I-1:0] pc_d1;
reg [DEPTH_I-1:0] pc_d2;
reg [DEPTH_I-1:0] pc_d3;
reg [WIDTH_D-1:0] loop_counter;
reg [DEPTH_I-1:0] loop_end;
reg [DEPTH_I-1:0] loop_span;
wire [1:0] addr_mode_d_s1;
wire [1:0] addr_mode_a_s1;
wire [1:0] addr_mode_b_s1;
wire [DEPTH_REG-1:0] reg_d_addr_s1;
wire [DEPTH_REG-1:0] reg_a_addr_s1;
wire [DEPTH_REG-1:0] reg_b_addr_s1;
wire signed [OPERAND_BITS-1:0] ims_d_s1;
wire signed [OPERAND_BITS-1:0] ims_a_s1;
wire signed [OPERAND_BITS-1:0] ims_b_s1;
wire [WIDTH_I-1:0] inst;
reg [WIDTH_I-1:0] inst_d1;
reg [WIDTH_I-1:0] inst_d2;
wire [1:0] addr_mode_d;
wire [1:0] addr_mode_a;
wire [1:0] addr_mode_b;
wire reg_mode_a;
wire reg_mode_b;
wire [6:0] op;
wire is_type_normal;
wire not_increment;
wire [DEPTH_REG-1:0] reg_d_addr;
wire [DEPTH_REG-1:0] reg_a_addr;
wire [DEPTH_REG-1:0] reg_b_addr;
wire [15:0] im16;
wire signed [REG_IM_BITS-1:0] ims_a;
wire signed [REG_IM_BITS-1:0] ims_b;
reg req_stop;
reg req_stop_d1;
reg [WIDTH_D-1:0] source_a;
reg [WIDTH_D-1:0] source_b;
// register file
reg [WIDTH_D-1:0] reg_file [0:(1 << DEPTH_REG)-1];
integer i;
// debug
wire [6:0] debug_op;
assign debug_op = inst[6:0];
// decode(stage1)
assign inst = ((stopped == TRUE) || (req_stop == TRUE)) ? NOP_OP : mem_i_r;
assign addr_mode_d_s1 = inst[12:11];
assign addr_mode_a_s1 = inst[10:9];
assign addr_mode_b_s1 = inst[8:7];
assign reg_d_addr_s1 = inst[DEPTH_REG+26-1:26];
assign reg_a_addr_s1 = inst[DEPTH_REG+20-1:20];
assign reg_b_addr_s1 = inst[DEPTH_REG+14-1:14];
assign ims_d_s1 = inst[OPERAND_BITS+26-1:26];
assign ims_a_s1 = inst[OPERAND_BITS+20-1:20];
assign ims_b_s1 = inst[OPERAND_BITS+14-1:14];
// decode(stage2)
assign op = inst_d2[6:0];
assign is_type_normal = inst_d2[6];
assign addr_mode_d = inst_d2[12:11];
assign addr_mode_a = inst_d2[10:9];
assign addr_mode_b = inst_d2[8:7];
assign reg_d_addr = inst_d2[DEPTH_REG+26-1:26];
assign reg_a_addr = inst_d2[DEPTH_REG+20-1:20];
assign reg_b_addr = inst_d2[DEPTH_REG+14-1:14];
assign im16 = inst_d2[31:16];
assign reg_mode_a = inst_d2[OPERAND_BITS+20-1];
assign reg_mode_b = inst_d2[OPERAND_BITS+14-1];
assign ims_a = inst_d2[REG_IM_BITS+20-1:20];
assign ims_b = inst_d2[REG_IM_BITS+14-1:14];
// manual pc increment
assign not_increment = ((stopped == TRUE) || (req_stop == TRUE) || (op == I_HALT) || (op == I_BC) || (op == I_BL) || (op == I_BA)) ? 1'b1 : 1'b0;
// switch source
// source_a
always @*
begin
if (addr_mode_a != ADDR_MODE_0)
begin
source_a = mem_d_r_a;
end
else
begin
if (reg_mode_a == TRUE)
begin
source_a = ims_a;
end
else
begin
source_a = reg_file[reg_a_addr];
end
end
end
// source_b
always @*
begin
if (addr_mode_b != ADDR_MODE_0)
begin
source_b = mem_d_r_b;
end
else
begin
if (reg_mode_b == TRUE)
begin
source_b = ims_b;
end
else
begin
source_b = reg_file[reg_b_addr];
end
end
end
// switch operation
function [WIDTH_D-1:0] result
(
input [6:0] op_result
);
begin
case (op_result)
I_ADD: result = source_a + source_b;
I_SUB: result = source_a - source_b;
I_AND: result = source_a & source_b;
I_OR: result = source_a | source_b;
I_XOR: result = source_a ^ source_b;
I_NOT: result = ~source_a;
I_SR: result = source_a >> source_b;
I_SL: result = source_a << source_b;
I_SRA: result = $signed(source_a) >>> source_b;
`ifdef DISABLE_MUL
`else
I_MUL: result = $signed(source_a) * $signed(source_b);
`endif
default: result = ZERO;
endcase
end
endfunction
// mem_d_we condition
assign mem_d_we_sig = (addr_mode_d != ADDR_MODE_0) & (is_type_normal | ((op == I_MV) & ((reg_file[SP_REG_CP] != ZERO))));
always @(posedge clk)
begin
if (reset == TRUE)
begin
loop_counter <= ZERO;
loop_end <= ZERO;
loop_span <= ZERO;
mem_d_addr_w_d0 <= ZERO;
mem_d_addr_w_s_d0 <= ZERO;
mem_d_addr_r_a <= ZERO;
mem_d_addr_r_a_s <= ZERO;
mem_d_addr_r_b <= ZERO;
mem_d_addr_r_b_s <= ZERO;
mem_d_addr_w_d1 <= ZERO;
mem_d_addr_w <= ZERO;
mem_d_w <= ZERO;
mem_d_we <= ZERO;
mem_i_addr_r <= ZERO;
inst_d1 <= ZERO;
inst_d2 <= ZERO;
pc_d1 <= ZERO;
pc_d2 <= ZERO;
pc_d3 <= ZERO;
stopped <= TRUE;
req_stop <= FALSE;
req_stop_d1 <= FALSE;
/*
for (i = 0; i < (1 << DEPTH_REG); i = i + ONE)
begin
reg_file[i] <= ZERO;
end
*/
end
else
begin
// delay
inst_d1 <= inst;
inst_d2 <= inst_d1;
pc_d3 <= pc_d2;
pc_d2 <= pc_d1;
pc_d1 <= mem_i_addr_r;
mem_d_we <= mem_d_we_sig;
mem_d_addr_w_d1 <= mem_d_addr_w_d0;
// mem_d_addr_w: d2
mem_d_addr_w <= mem_d_addr_w_d1;
req_stop_d1 <= req_stop;
if (req_stop_d1 == TRUE)
begin
stopped <= TRUE;
req_stop <= FALSE;
end
if (stopped == FALSE)
begin
// addressing
case (addr_mode_d_s1)
ADDR_MODE_0:
begin
mem_d_addr_w_d0 <= mem_d_addr_w_d0;
mem_d_addr_w_s_d0 <= mem_d_addr_w_s_d0;
end
ADDR_MODE_1:
begin
mem_d_addr_w_d0 <= reg_file[reg_d_addr_s1][DEPTH_D-1:0];
mem_d_addr_w_s_d0 <= reg_file[reg_d_addr_s1][DEPTH_D-1:0];
end
ADDR_MODE_2:
begin
mem_d_addr_w_d0 <= mem_d_addr_w_s_d0;
mem_d_addr_w_s_d0 <= mem_d_addr_w_s_d0 + reg_file[reg_d_addr_s1][DEPTH_D-1:0];
end
ADDR_MODE_3:
begin
mem_d_addr_w_d0 <= $signed(mem_d_addr_w_s_d0) + ims_d_s1;
mem_d_addr_w_s_d0 <= mem_d_addr_w_s_d0;
end
endcase
case (addr_mode_a_s1)
ADDR_MODE_0:
begin
mem_d_addr_r_a <= mem_d_addr_r_a;
mem_d_addr_r_a_s <= mem_d_addr_r_a_s;
end
ADDR_MODE_1:
begin
mem_d_addr_r_a <= reg_file[reg_a_addr_s1][DEPTH_D-1:0];
mem_d_addr_r_a_s <= reg_file[reg_a_addr_s1][DEPTH_D-1:0];
end
ADDR_MODE_2:
begin
mem_d_addr_r_a <= mem_d_addr_r_a_s;
mem_d_addr_r_a_s <= mem_d_addr_r_a_s + reg_file[reg_a_addr_s1][DEPTH_D-1:0];
end
ADDR_MODE_3:
begin
mem_d_addr_r_a <= $signed(mem_d_addr_r_a_s) + ims_a_s1;
mem_d_addr_r_a_s <= mem_d_addr_r_a_s;
end
endcase
case (addr_mode_b_s1)
ADDR_MODE_0:
begin
mem_d_addr_r_b <= mem_d_addr_r_b;
mem_d_addr_r_b_s <= mem_d_addr_r_b_s;
end
ADDR_MODE_1:
begin
mem_d_addr_r_b <= reg_file[reg_b_addr_s1][DEPTH_D-1:0];
mem_d_addr_r_b_s <= reg_file[reg_b_addr_s1][DEPTH_D-1:0];
end
ADDR_MODE_2:
begin
mem_d_addr_r_b <= mem_d_addr_r_b_s;
mem_d_addr_r_b_s <= mem_d_addr_r_b_s + reg_file[reg_b_addr_s1][DEPTH_D-1:0];
end
ADDR_MODE_3:
begin
mem_d_addr_r_b <= $signed(mem_d_addr_r_b_s) + ims_b_s1;
mem_d_addr_r_b_s <= mem_d_addr_r_b_s;
end
endcase
// loop counter
if (loop_end == mem_i_addr_r)
begin
if ((loop_counter != ZERO) && (op != I_LOOP))
begin
loop_counter <= loop_counter - ONE;
end
end
// increment pc (prefetch address)
if (!not_increment)
begin
if (loop_end == mem_i_addr_r)
begin
if (loop_counter == ZERO)
begin
mem_i_addr_r <= mem_i_addr_r + ONE;
end
else
begin
mem_i_addr_r <= mem_i_addr_r + loop_span;
end
end
else
begin
mem_i_addr_r <= mem_i_addr_r + ONE;
end
end
// execution
if (is_type_normal)
begin
// for normal instructions
case (addr_mode_d)
ADDR_MODE_0:
begin
reg_file[reg_d_addr] <= result(op);
end
ADDR_MODE_1, ADDR_MODE_2, ADDR_MODE_3:
begin
mem_d_w <= result(op);
end
endcase
end
else
begin
// special instructions
case (op)
I_HALT:
begin
req_stop <= TRUE;
end
I_NOP:
begin
end
I_MV:
begin
if (reg_file[SP_REG_CP] != ZERO)
begin
case (addr_mode_d)
ADDR_MODE_0:
begin
reg_file[reg_d_addr] <= source_a;
end
ADDR_MODE_1, ADDR_MODE_2, ADDR_MODE_3:
begin
mem_d_w <= source_a;
end
endcase
end
end
I_MVI:
begin
reg_file[SP_REG_MVI] <= im16;
end
I_MVIH:
begin
if (WIDTH_D >= 16)
begin
reg_file[SP_REG_MVI] <= {im16, reg_file[SP_REG_MVI][15:0]};
end
end
I_CEQ:
begin
if (source_a == source_b)
begin
reg_file[SP_REG_CP] <= FFFF;
end
else
begin
reg_file[SP_REG_CP] <= ZERO;
end
end
I_CGT:
begin
if (source_a > source_b)
begin
reg_file[SP_REG_CP] <= FFFF;
end
else
begin
reg_file[SP_REG_CP] <= ZERO;
end
end
I_CGTA:
begin
if ($signed(source_a) > $signed(source_b))
begin
reg_file[SP_REG_CP] <= FFFF;
end
else
begin
reg_file[SP_REG_CP] <= ZERO;
end
end
I_BC:
begin
if (reg_file[SP_REG_CP] == ZERO)
begin
mem_i_addr_r <= mem_i_addr_r + ONE;
end
else
begin
mem_i_addr_r <= pc_d3 + reg_file[SP_REG_BA];
end
end
I_BL:
begin
reg_file[SP_REG_LINK] <= pc_d3 + DELAY_SLOT_P1;
mem_i_addr_r <= pc_d3 + reg_file[SP_REG_BA];
end
I_BA:
begin
mem_i_addr_r <= reg_file[SP_REG_BA];
end
I_LOOP:
begin
loop_counter <= reg_file[SP_REG_LOOP_COUNTER];
loop_end <= pc_d3 + reg_file[SP_REG_LOOP_END][DEPTH_I-1:0];
loop_span <= reg_file[SP_REG_LOOP_SPAN][DEPTH_I-1:0];
end
default: ;
endcase
end
end
else
begin
// if stopped == TRUE
if (resume_pulse == TRUE)
begin
stopped <= FALSE;
mem_i_addr_r <= mem_i_addr_r + ONE;
end
end
end
end
// create resume_pulse
always @(posedge clk)
begin
resume_d1 <= resume;
end
assign resume_pulse = ((resume == TRUE) && (resume_d1 == FALSE)) ? TRUE : FALSE;
endmodule